ComfyUI_examples 翻译笔记
在学习 ComfyUI 的过程中直接把官方的 Examples 文档翻译完了。
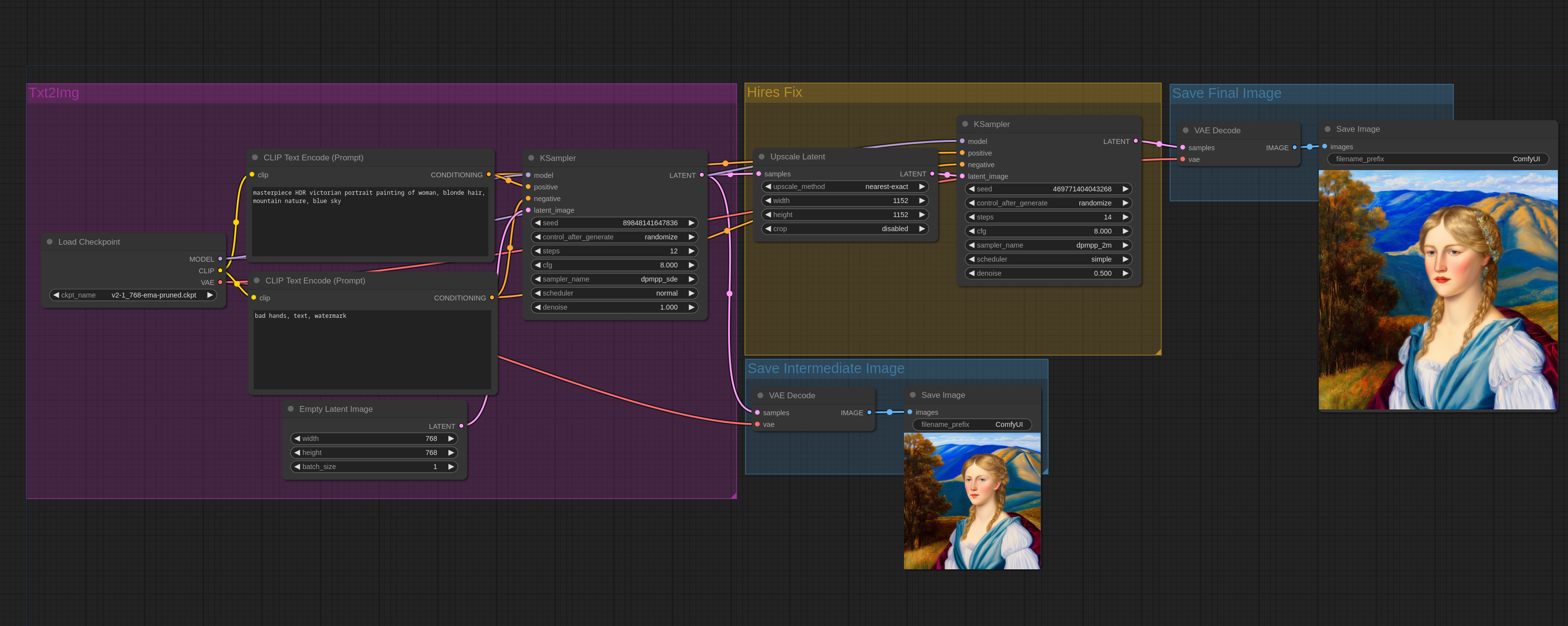
1. 2 Pass Txt2Img (Hires fix) Examples
这里是一些示例,向你展示应该如何实现“Hires Fix”(高清修复)这个功能。
GPT 解释 Hires Fix:
“Hires fix” 或者又称为高分辨率修复,是一种在深度学习和图像生成领域中用来提高图像分辨率和细节的技术。GPT 解释 2 pass workflow:
在软件开发和界面设计中,”2 pass workflow” 或 “two-pass workflow” 是指一个过程或任务在完成时需要两个阶段或步骤。具体到 ComfyUI 或类似的界面框架中,这通常涉及到两个主要的过程:第一遍(First Pass):在这一阶段,系统会进行初步的处理,例如收集数据、进行初步计算或者确定哪些元素需要在界面上展示。这一步骤通常是准备阶段,为第二遍处理做好铺垫。
第二遍(Second Pass):在第一遍处理之后,第二遍通常涉及更细致或针对性的处理。例如,在界面布局中,第一遍可能确定了哪些组件需要显示,而第二遍则可能涉及到具体的布局计算,如组件的位置和大小调整,以确保最佳的用户体验。
在界面设计和开发中,两遍工作流可以帮助开发者更高效地处理和渲染界面,尤其是在需要处理大量数据或复杂交互时。通过将处理过程分解为两个阶段,可以优化性能和响应速度,同时降低错误和问题的风险。
你可以直接把这些图片拖动到 ComfyUI 中来观察完整的 workflow。
Hires fix 是先创建了一张低清晰度的图片,然后通过 img2img 来放大它。请注意,在 ComfyUI 中 txt2img 和 img2img 是一样的节点。Txt2img 节点是通过传入一张负有最大噪点的空图片给采样器节点来实现的。
以下是一个简单的 ComfyUI workflow,可以实现基础的 latent(潜在空间)放大:
非 latent 放大
这里是一个在放大步骤中使用了 ESRGAN 放大器的例子,因为ESRGAN 是直接在 pixel space(像素空间)中运行的,所以,图片必须转换成像素控件然后放大后再返回到 latent space(潜在空间)。
译者:
这里用到一个 RealESRGAN_x4plus.pth 模型需要下载。
更多示例
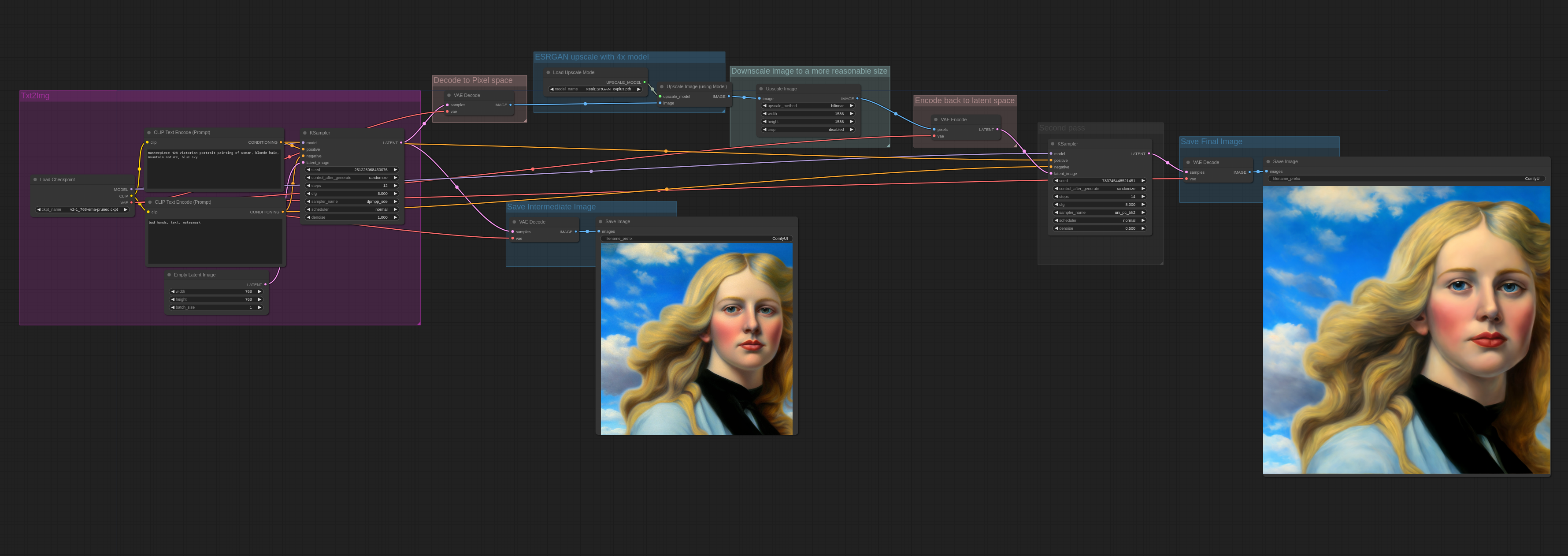
这里是一个更加复杂的 2 pass workflow (两道工序工作流),这张图是先从 WD1.5 beta 3 illusion 模型生成,然后通过 latent 放大方式放大,之后再传给 cardosAnime_v10 处理。

译者:
“CLIP Set Last Layer”节点可以用来设置CLIP模型中从哪一个输出层获取文本嵌入。文本转换为嵌入是通过文本在CLIP模型的各个层中被转换实现的。虽然传统上扩散模型是基于CLIP中最后一层的输出进行条件化的,但一些扩散模型已经基于较早的层进行了条件化,并且在使用最后一层的输出时可能不会工作得那么好。
2. Img2Img Examples
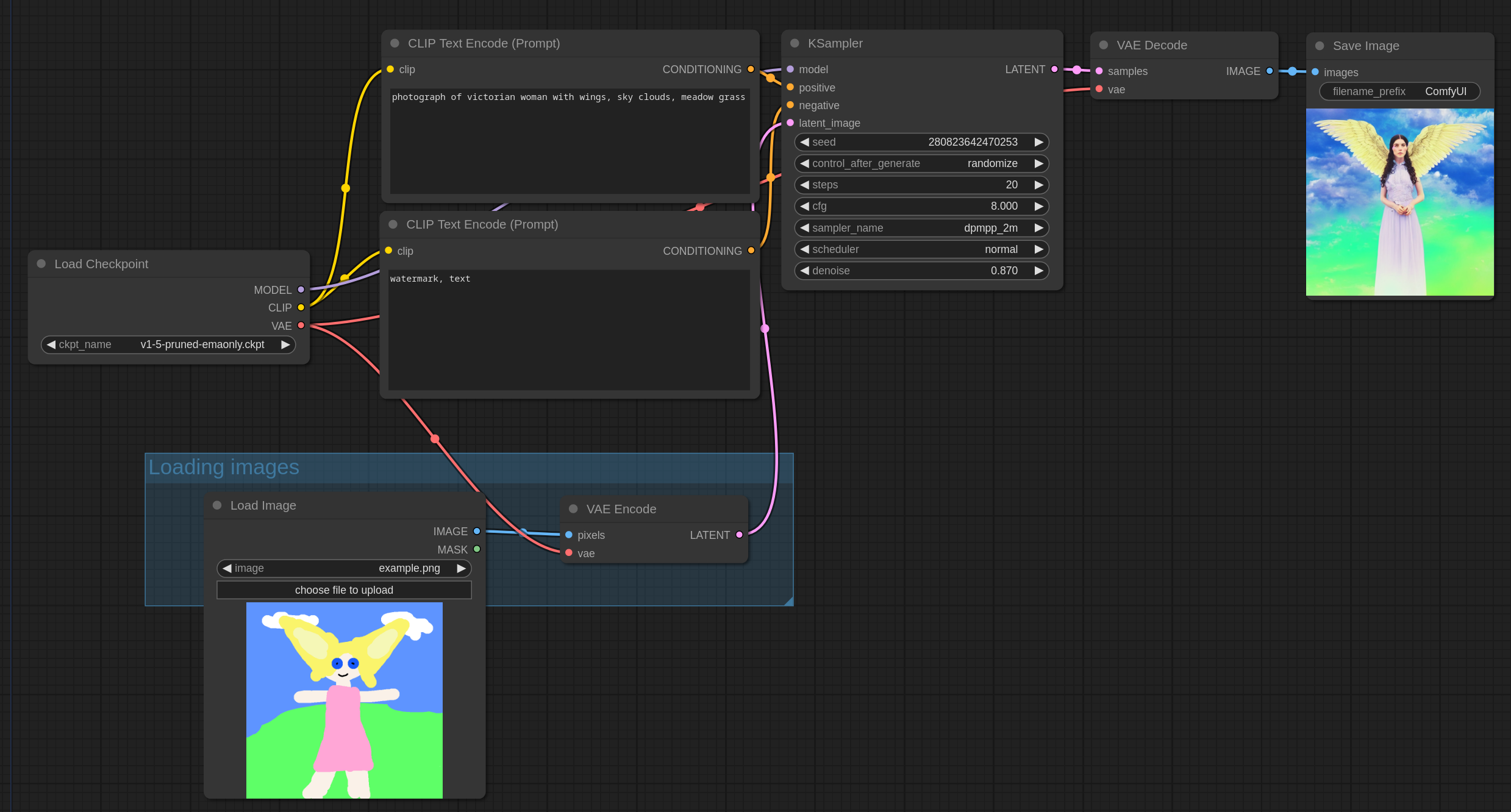
这里是一个展示如何实现 img2img 的例子。
你可以直接把这些图片拖动到 ComfyUI 中来观察完整的 workflow。
Img2Img 需要先加载一张图片来工作,先将它通过 VAE 转换为 latent space,然后用低于 1.0 的 denoise 进行采样。denoise 控制的是添加到图片的噪点数量,噪点添加的越少,图片改变的越少。
输入图片需要被放置在 input 文件夹中。
一个简单的 img2img 看起来长下面这样,和默认的 txt2img 流程很像,不过 denoise 被设置在了 0.87,也传了一张真实的图片而非空图片给 KSampler。
3. Inpaint Examples
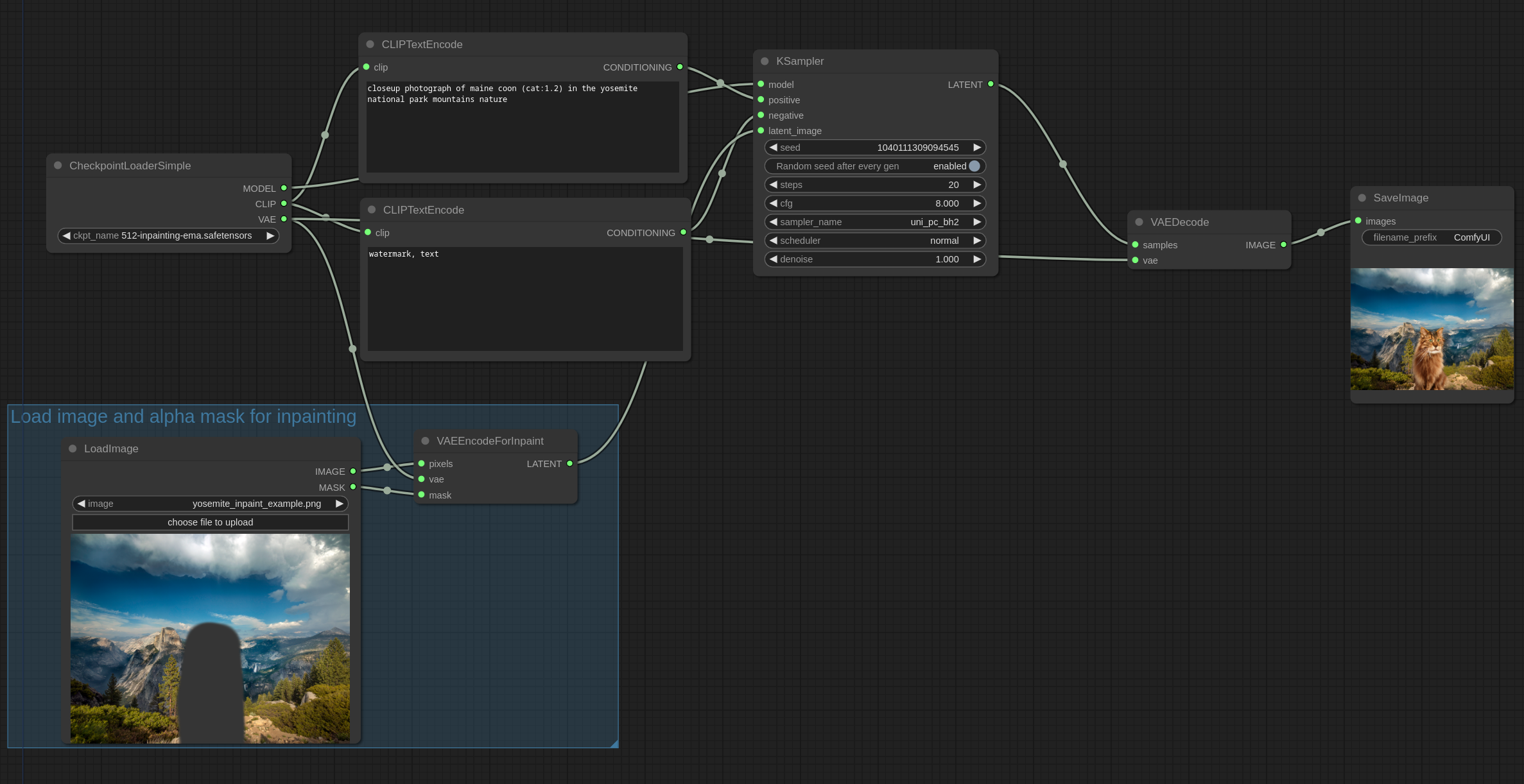
在这个例子中,我们使用这张图片。下载并将其放置在输入文件夹中

这张图片有一部分是通过 gimp (GNU Image Manipulation Program)擦除了一部分。alpha 通道将用做修复的蒙版。如果你也是用 GIMP,请确保你保存了透明像素的值,以便获取最佳的效果。
ComfyUI 也有一个蒙版编辑器,可以通过在 Load Image 图片中右键图片然后点击“Open in MaskEditor”来使用。
可以直接把下面的图片加载到 ComfyUI 中来查看完整的 workflow 。
使用 v2 Inpainting 模型在图像上修补一只猫。

修补一个女人

如果不是专门的 inpainting 模型也可以用。这里就是一个例子,用的是 anythingV3 model:

Outpainting
你也可以使用相似的 workflow 来实现 outpainting 功能。Outpainting 和 inpainting 是一样的,这里有一个“Pad Image for Outpainting”节点,可以根据合适的蒙版自动填补图像来进行 outpainting。在下面的这个例子中,这个图像将会被 outpainted:

使用 v2 inpainting 模型和 “Pad Image for Outpainting” 节点(把它加载到 ComfyUI 中来看完整的 workflow ):

4. Lora Examples
这里是一些关于你应该如何去使用 Lora 的例子。所有类型的 LoRA 都可以使用这个方式,比如 Lycoris,loha,lokr,locon 等等。
你可以把这些图片加载到 ComfyUI 中来获得完整的 workflow 。
Lora 好比一个补丁,作用在主模型和 CLIP 模型上,所以为了使用 Lora,你需要把它放在 models/loras 目录下,然后在 ComfyUI 中使用 LoraLoader,就像这样:
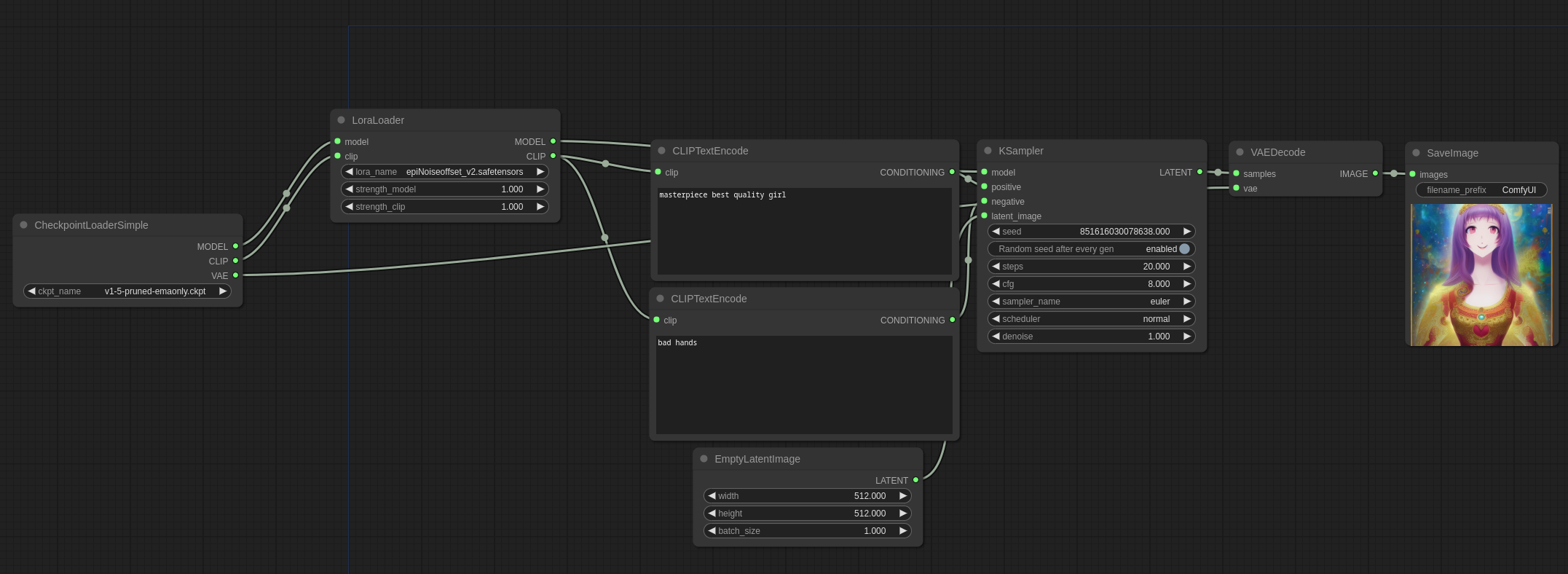
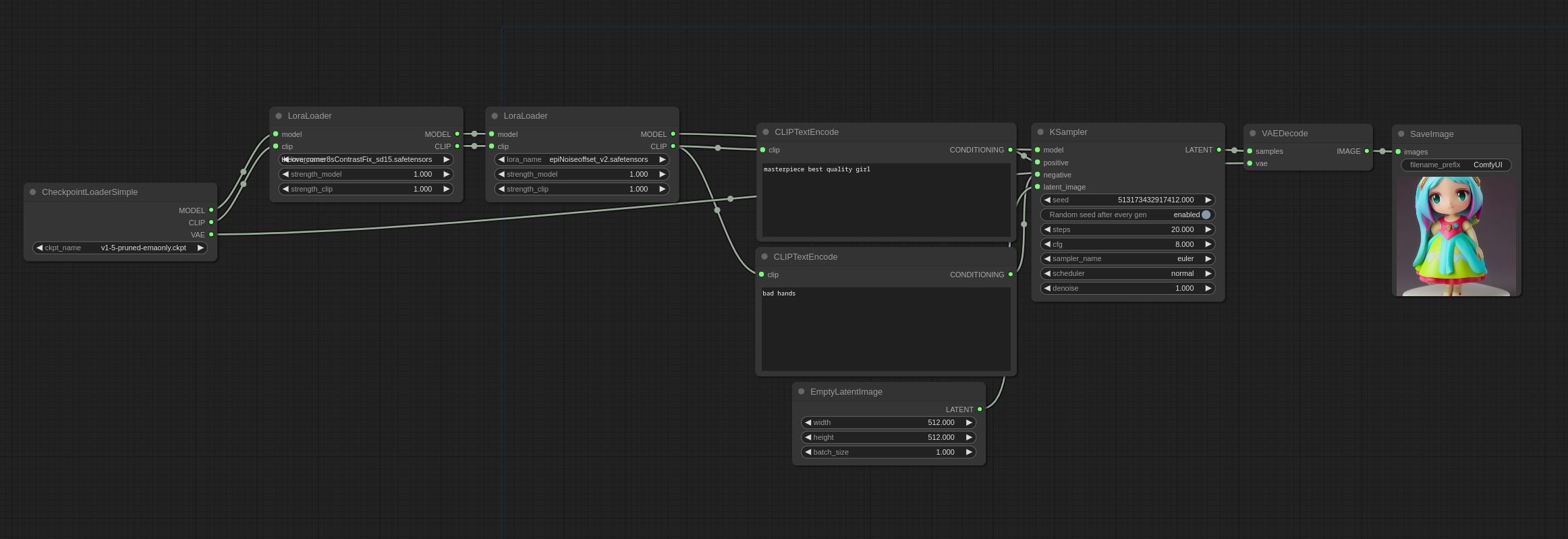
你可以通过串联多个 LoraLoader 的方式使用多个 Lora ,就像这样:
5. Hypernetwork Examples
你可以把这些图片加载到 ComfyUI 中来获得完整的 workflow 。
Hypernetwork 是一个作用在主模型上的补丁,你需要把它放在 models/hypernetworks 目录下,然后在 ComfyUI 中使用 Hypernetwork Loader,就像这样:
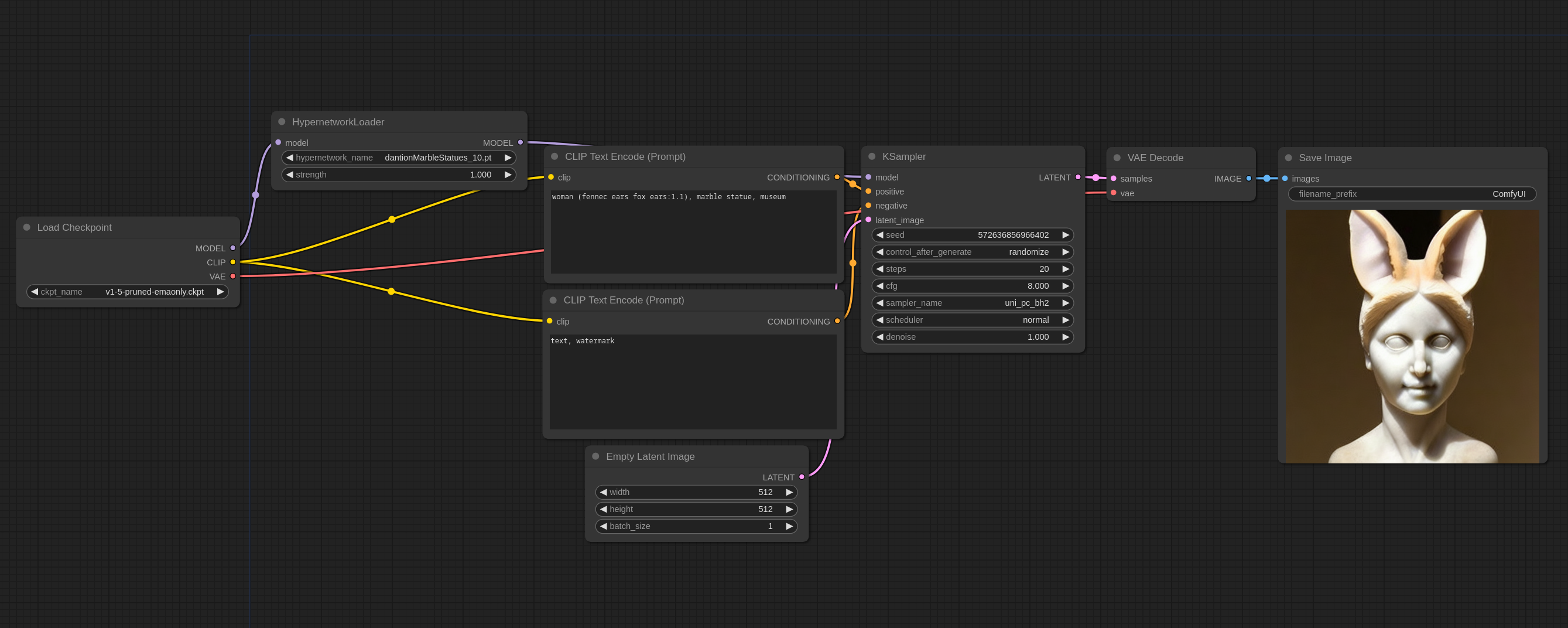
你可以通过串联多个 Hypernetwork Loader 的方式使用多个 hypernetwork。
6. Textual Inversion Embeddings Examples
这是一个展示如何使用 Textual Inversion/Embeddings 的例子。
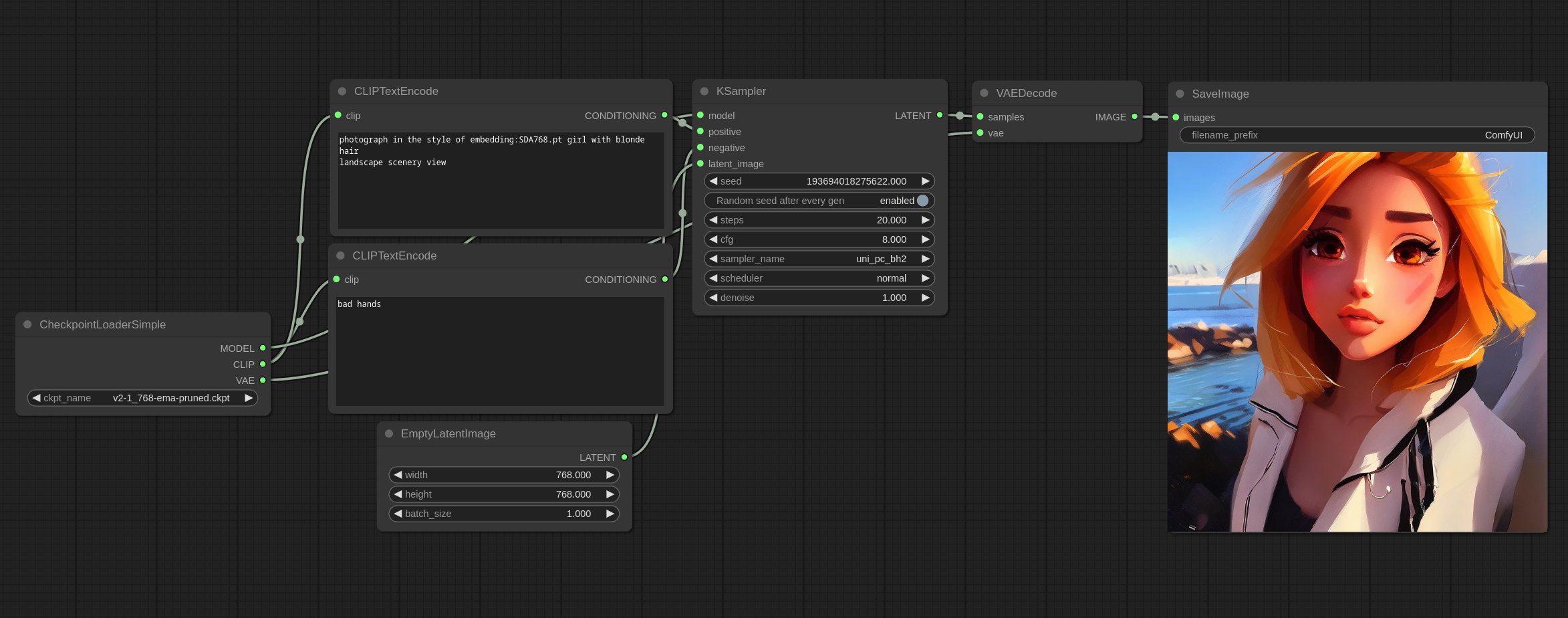
为了使用一个 embedding,你需要先将文件放在 models/embeddings 文件夹下,然后在你的 prompt 中使用,就像我在上图中使用 SDA768.pt 一样。
需要注意,你可以省略文件的后缀名,下面两种书写方式都是一样的:
embedding: SDA768.pt
embedding:SDA768
和其他 prompt 一样,你也可以设置 embedding 的强度:
(embedding:SDA768:1.2)
Embeddings 本质上就是一些自定义的词,所以在 prompt 中放置的位置很重要。
比如,如果你这样使用关于猫的一个 embedding:
red embedding:cat
这样大概率会给你一只红色的猫。
7. Upscale Model Examples
这是一个教你如何用 upscale model(放大模型),比如 ESRGAN,的例子,把它们放在 models/upscale_models 文件夹下,然后使用 UpscaleModelLoader 节点来加载,并通过 ImageUpscaleWithModel 节点来使用。
这里是一个例子:
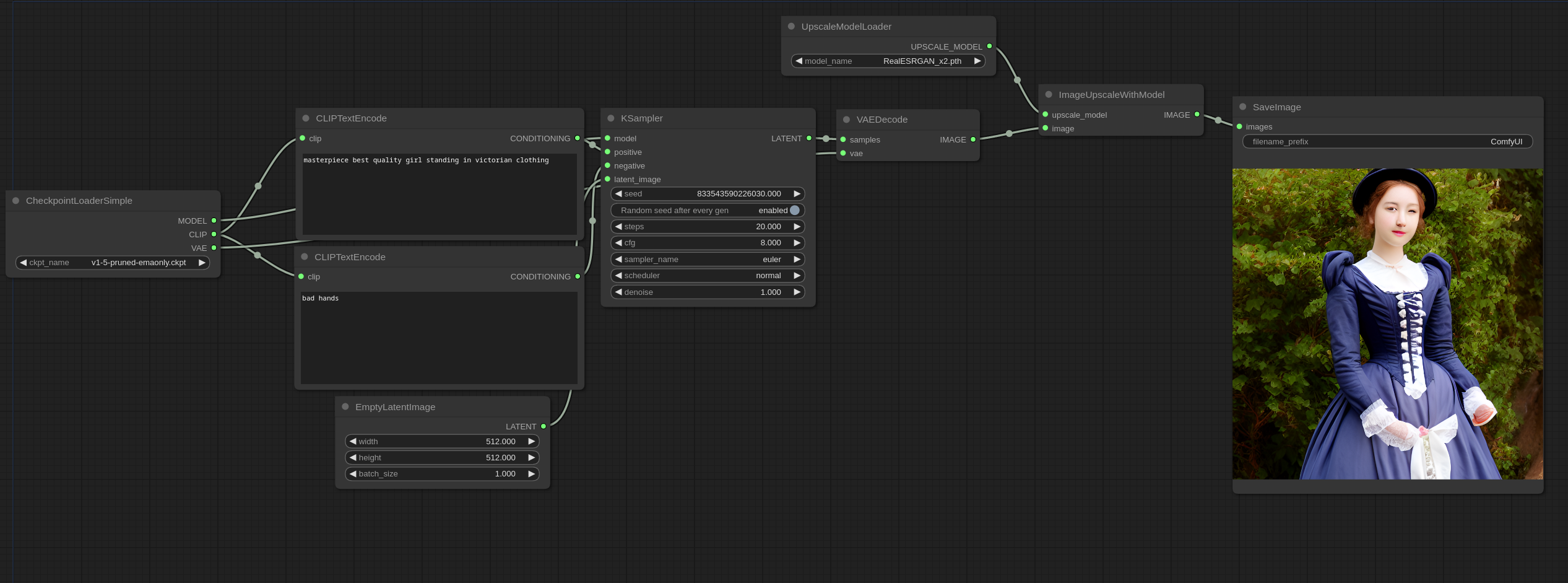
你可以把这张图片加载到 ComfyUI 中来查看完整的 workflow 。
如果你在找一些可用的 upscale model,你可以访问 OpenModelDB 。
GPT 回答 Upscale Model 和 Hires fix 在放大图片上有什么不同:
Stable Diffusion的Upscale Model和Hires fix都是用于提高图像分辨率和细节的工具,但它们在处理方式和细节增强上有所不同:
Upscale Model:
这种模型通常用于将图像的分辨率从较低的分辨率放大到更高的分辨率。
它通过添加更多的像素点来增加图像的总体尺寸,同时尽量保持图像内容的真实性和质量。
Upscale Model主要关注于图像尺寸的增加,适合于需要在不丢失过多细节的情况下查看更大版本图像的场景。
Hires Fix:
Hires fix更专注于在高分辨率图像生成时改善和修复细节。
它通常用于已经是高分辨率的图像,但可能在某些细节上不够清晰或存在一些视觉瑕疵。
Hires fix努力在保持高分辨率的同时提升图像质量,改进图像的局部细节,使其更加锐利和准确。
总的来说,如果你需要从较小的图像创建一个更大但保持质量的版本,Upscale Model是合适的选择。而如果你的图像已经具备较高分辨率,但需要在细节上进行改进或修复,Hires fix可能是更好的选择。
8. Area Composition Examples
这里是一些教你如何使用 ConditioningSetArea 节点的例子。你可以把这些图片拖动到 ComfyUI 中来查看完整的 workflow 。
Area composition with Anything-V3 + second pass with AbyssOrangeMix2_hard
这张图片包含了4个不同的区域,夜晚、晚上、白天、早晨。

workflow 看起来是这样的:
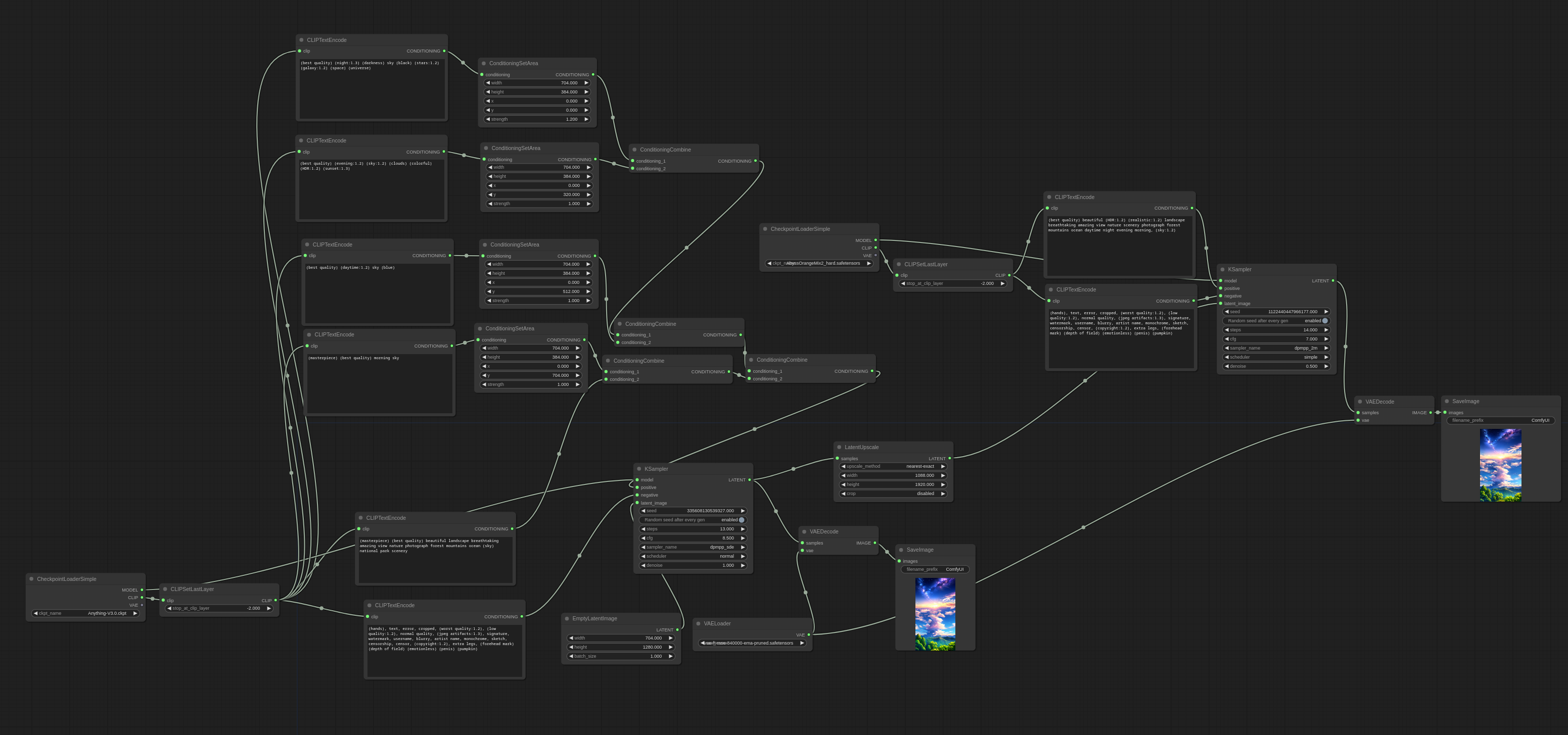
这张图片也是同样的四个区域,不过顺序反了一下:

然后通过添加另一个区域 prompt ,可以在图片中心靠下的位置添加一个主体。

Increasing Consistency of images with Area Composition
Stable Diffusion 在生成接近512x512分辨率的正方形图像时,能够创造出最 consistent (一致) 的图像效果。但是如果我们想生成一张 16:9 比例的图像呢?让我们生成一张带有坐姿的 16:9 的图片吧。如果正常生成,成功率会很低,因为肢体会在图像上不自然的延伸,可能还会有其他的 consistent 问题。
通过使用 Area Composition 方法,给主体划定一个正方形区域,consistency 会更加高,因为它和图像的其余部分是同时生成的,最后整体图像的效果会更好。
下面这个 workflow 用了 Anything-V3 模型,还用了带有 area composition 的 2 pass workflow,area composition 被用在第一道工序中,用来生成图像左侧的主体。第二道则只是为了提高分辨率,如果你觉得 1280×704 分辨率 OK 的话你也可以跳过第二道。

使用区域 prompt 在图片的右边添加了一个红色头发的主体。
第一道输出(1280×704):

第二道输出(1920×1080):

第二道输出的图像展示了 Stable Diffusion 生成的一种特点。第二遍处理时没有区域提示。很容易注意到,左边主体的头发是金色的,但是带有粉红色的光泽,第二位主体的头发是粉红色的,而第一道输出的图片则是深红。这是因为 Stable Diffsuion 试图将整个图像保持一致性,其副作用之一就是将头发颜色融合在一起。
9. Noisy Latent Composition Examples
你可以把这些图片拖动到 ComfyUI 中来查看完整的 workflow 。
这里是一些 Noisy Latent Composition 的例子。Noisy Latent Composition 指的是,在图像完全去噪之前,在 latent 中,还带有噪点时进行合成。因为通常的形状比如 pose 和主体是在第一个采样步骤中被降噪,因此我们可以把一些特定 pose 的主体放置在图像中的任意位置,同时保持一定的 consistency。
这里是一个例子,这个例子把四张图融合到一起,一个背景和 3 个主体。总采样步数是 16。在 latent ,每种 prompt 都进行了 4 的采样。背景的分辨率是 1920×1088,主体每个都是 384×768。在这 4 步采样完成后,这些图片还是充满了噪点,然后这 3 个主体在适当羽化的条件下,被合成到了背景上。剩余的采样步骤(12 步)在合成后的图片上跑完。
下面这些例子是通过 WD1.5 beta 3 illusion 模型生成的。

然后改变了主体的位置:

可以看到,由带噪点的不同 latent 图片组成的主体之间,还是相互作用的,因为我在提示中添加了“holding hands”。也很容易注意到背景的 consistent 非常强,也说明了这个方法很强大。
这个技术还有一些限制,它无法控制主体的细节,比如眼睛的颜色。但是它似乎在主体的位置、姿势和总体颜色控制上表现地非常好。
10. ControlNet and T2I-Adapter Examples
请注意,在下面的例子中,原始图片都是直接从 ControlNet/T2I adapter 传过来的。
如果你想要产出好的结果,那需要给 ControlNet/T2I adapter 传入符合特定样式的图片,比如 depthmaps(深度图)、canny maps 边缘图等,具体格式取决于你使用的模型。
ControlNetApply 节点不会将常规图片转换成 depthmaps、canny maps 等特定样式的图片。你需要使用一些节点来预先处理这些图片。
你可以在这里找到最新的 controlnet 模型,或是它的 fp16 小模型版本。
对于 SDXL 模型,stability.ai 放出了 Controls Loras 的 rank 256 和 rank 128 版本,他们用起来就和普通的 ControlNet 模型文件一样。
ControlNet 的模型文件要放在 ComfyUI/models/controlnet 下。
Scribble ControlNet
关于如何使用 ControlNet 这里有一个简单的例子,用了 Scribble ControlNet 和 AnythingV3 模型。你可以把这张图加载到 ComfyUI 中来查看玩着的 workflow。
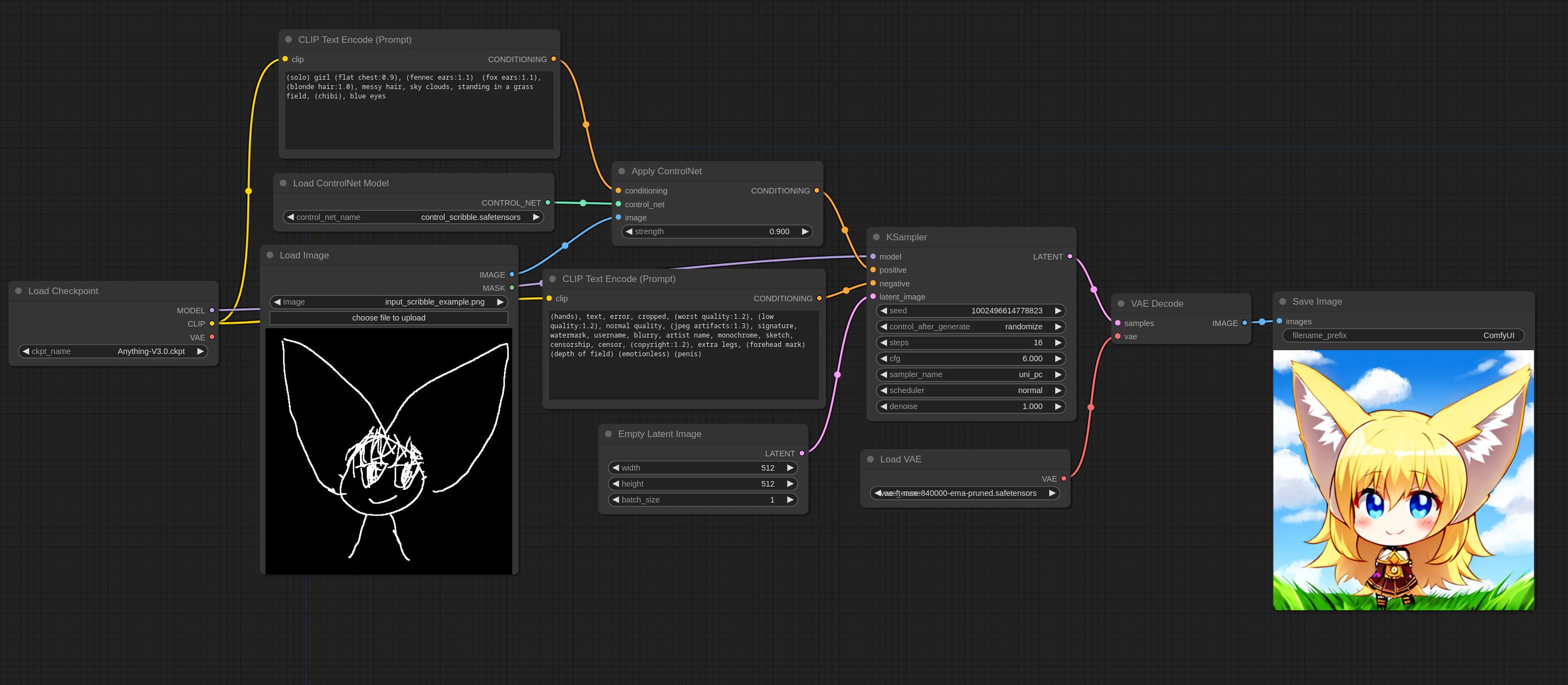
这张就是我在 workflow 中用到的输入图片:

T2I-Adapter vs ControlNets
我强烈推荐 T2I-Adapter ,它比 ControlNet 更加高效。使用 ControlNet 会显著降低图片生成的速度,而 T2I-Adapter 几乎对生成速度没有负面的影响。
ControlNet model 会在每轮 iteration(迭代)中都运行。而 T2I-Adapter 则之后运行一次。
在 ComfyUI 中 T2I-Adapter 的用法和 ControlNet 的用法一样,都是用 ControlNetLoader 节点。
这个是我在接下来的示例中会用到的图片,源地址

然后这是完整的 workflow:
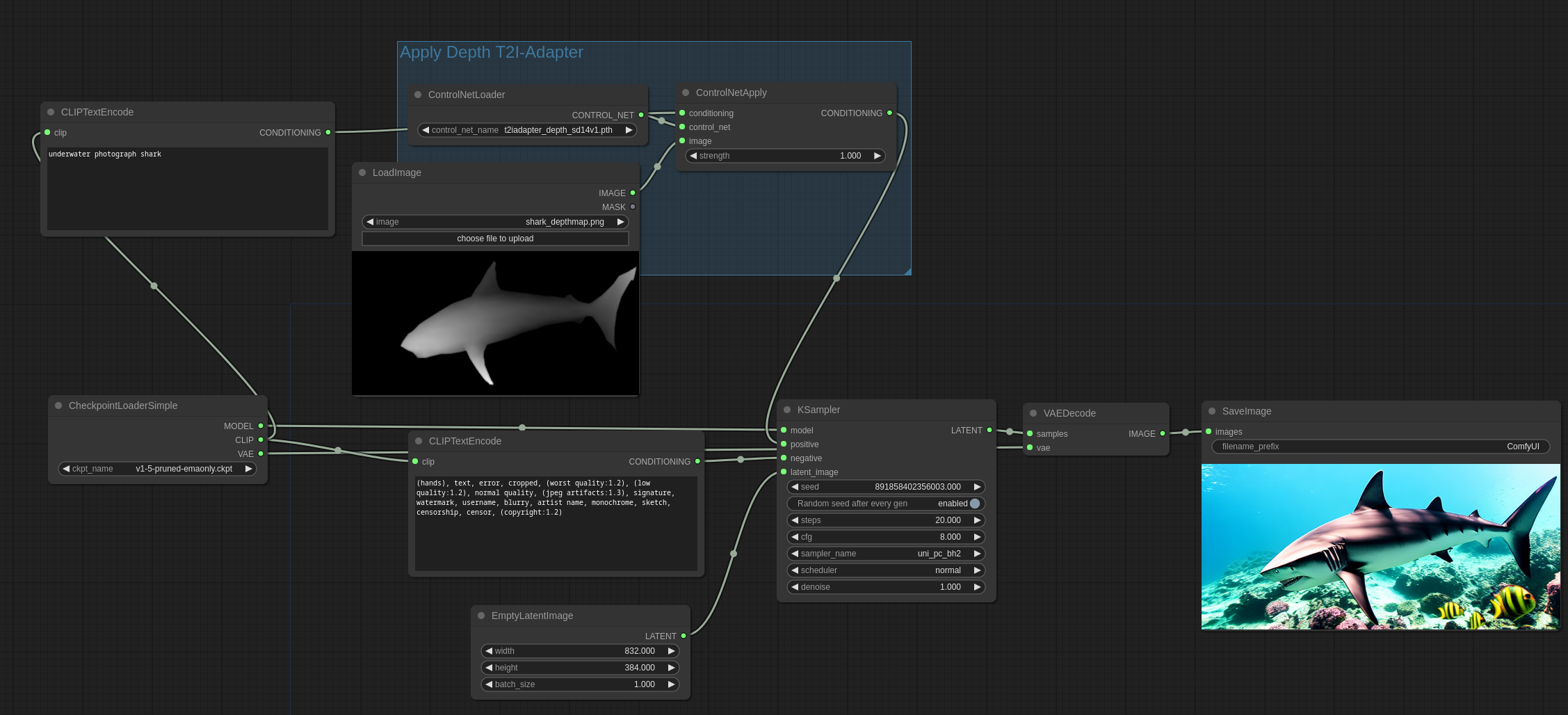
接下来是 Controlnet 深度模型的用法。需要注意的是,这个例子用了 DiffControlNetLoader 因为 controlnet 模型用的是一个 diff 模型(注意文件名称)。Diff controlnet 需要模型的权重被加载正确。DiffControlNetLoader 节点也可以被用在常规的 controlnet 上面,当加载一个常规的 controlnet 模型的时候,就和 ControlNetLoader 节点一样了。
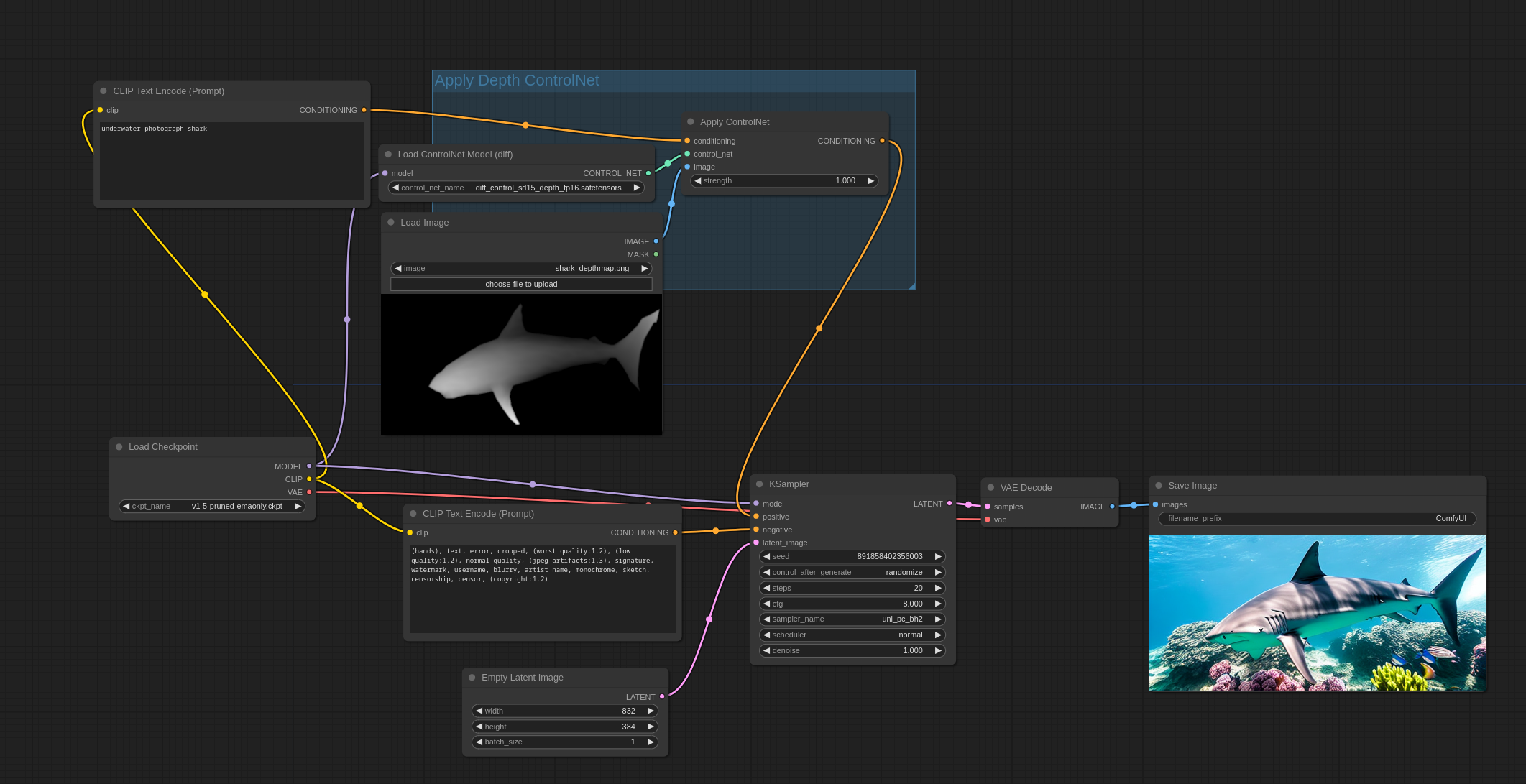
你可以直接把这些图片拖动到 ComfyUI 中来观察完整的 workflow。
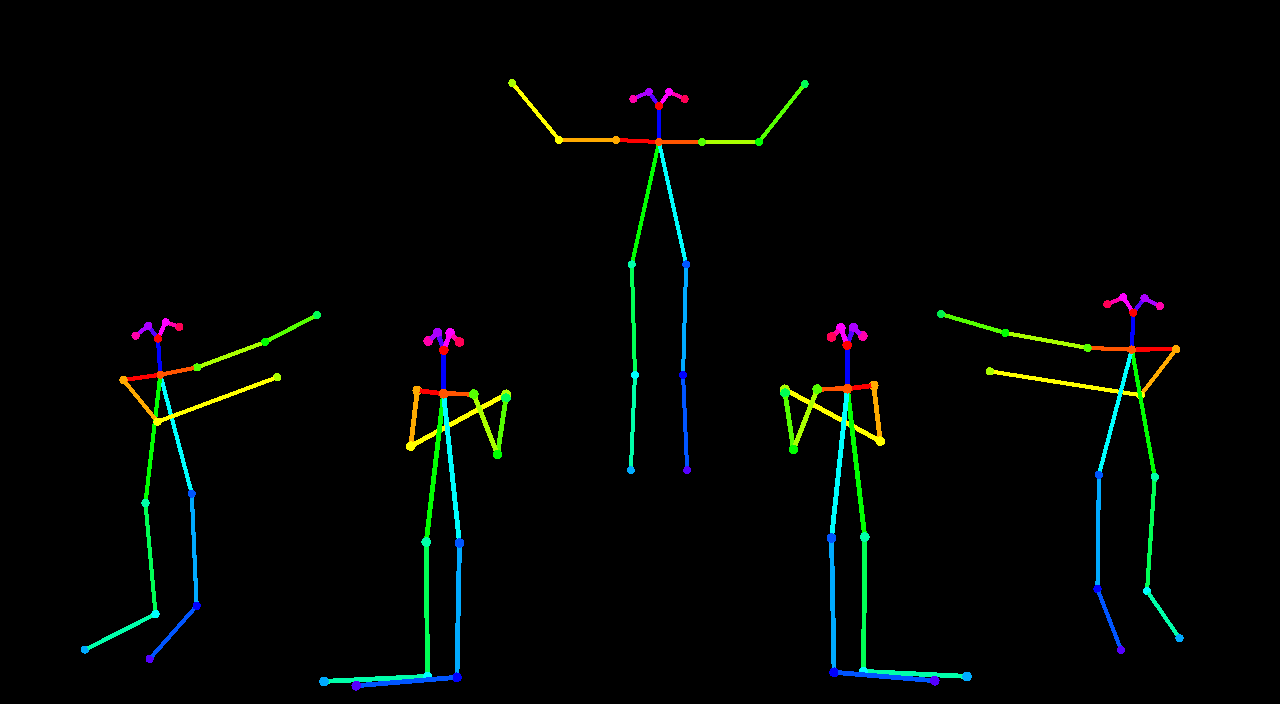
Pose ControlNet
这是我会在接下来的例子中用到的输入图片:
这里是一个例子,第一道工序用了 AnythingV3 加上 controlnet,第二道是没有用 controlnet,直接用 AOM3A3(abuss orange mix 3)。

你可以直接把这张图片拖动到 ComfyUI 中来观察完整的 workflow。
Mixing ControlNets
多个 ControlNet 和 T2I-Adapters 可以像下图一样一起用,会产生有趣的结果。
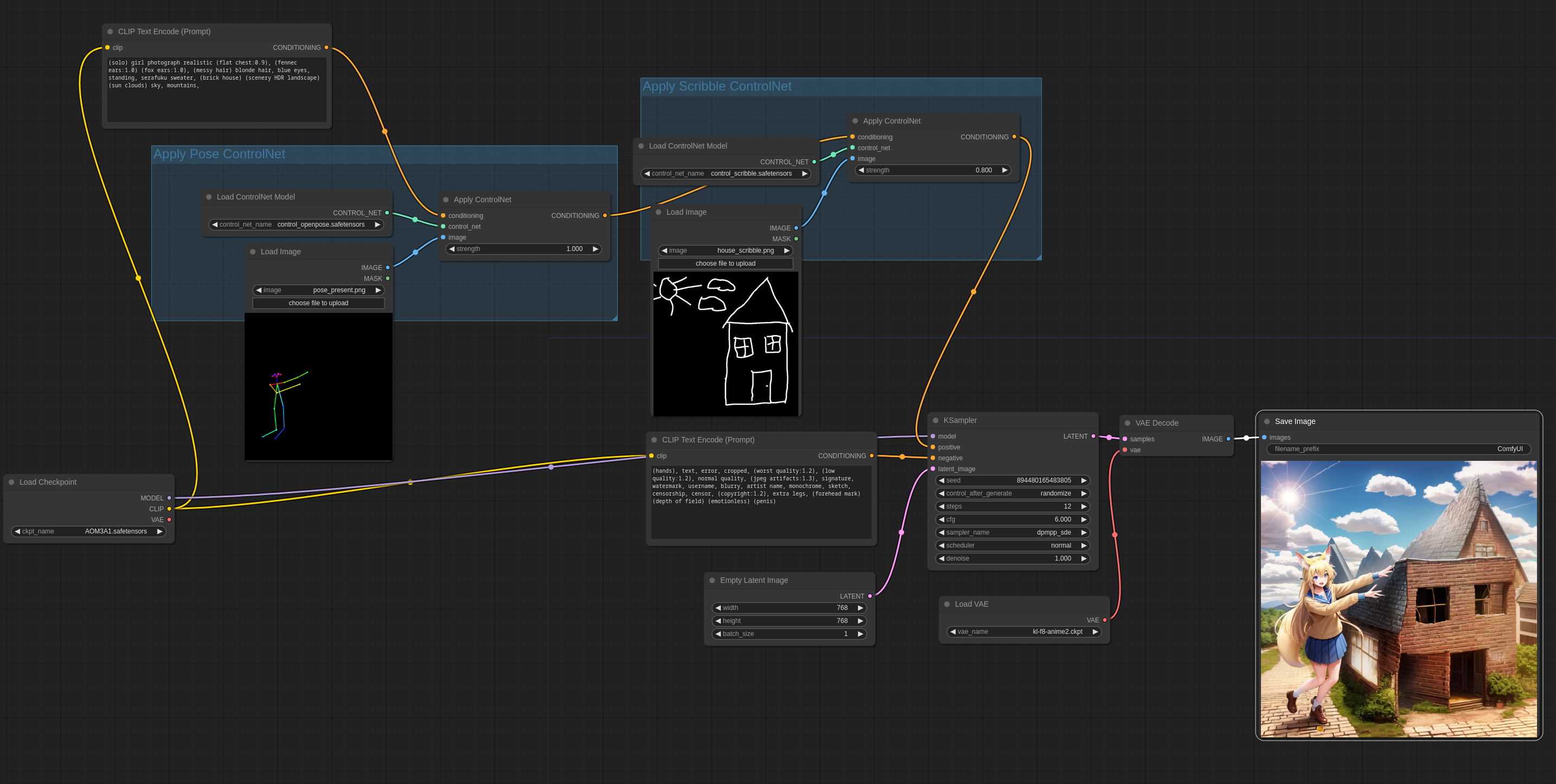
输入图片:
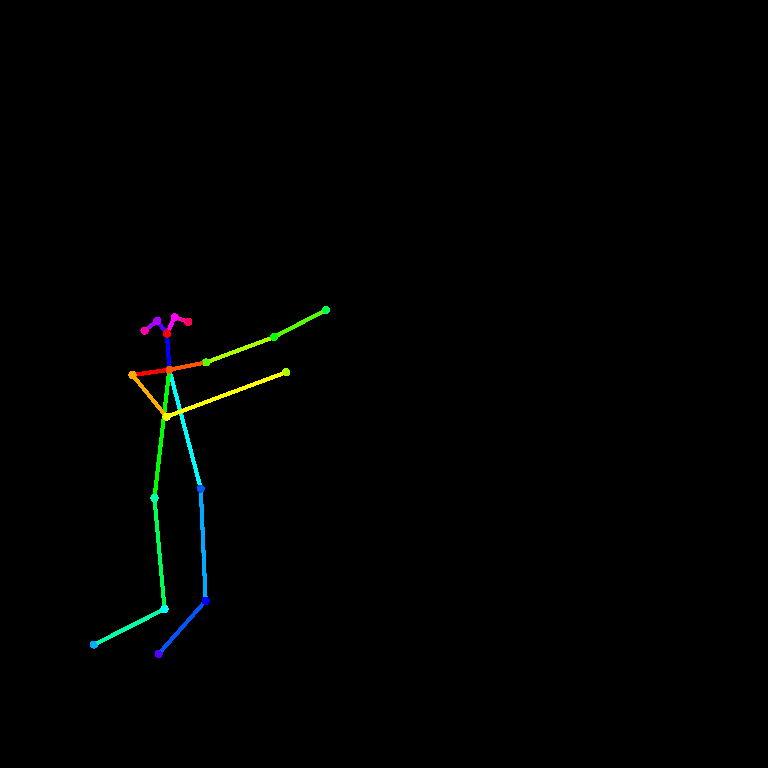

11. GLIGEN Examples
可以在这里下载受支持的 GLIGEN 模型文件的精简版本
把 GLIGEN 模型文件放在 ComfyUI/models/gligen 目录下。
Text box GLIGEN
text box GLIGEN 模型让你可以指定图像中多个物体的位置和大小。想要正确的使用它,你先正常的写 prompt,然后用 GLIGEN Textbox Apply 节点来指定 prompt 中特定的物体或概念的位置和尺寸。
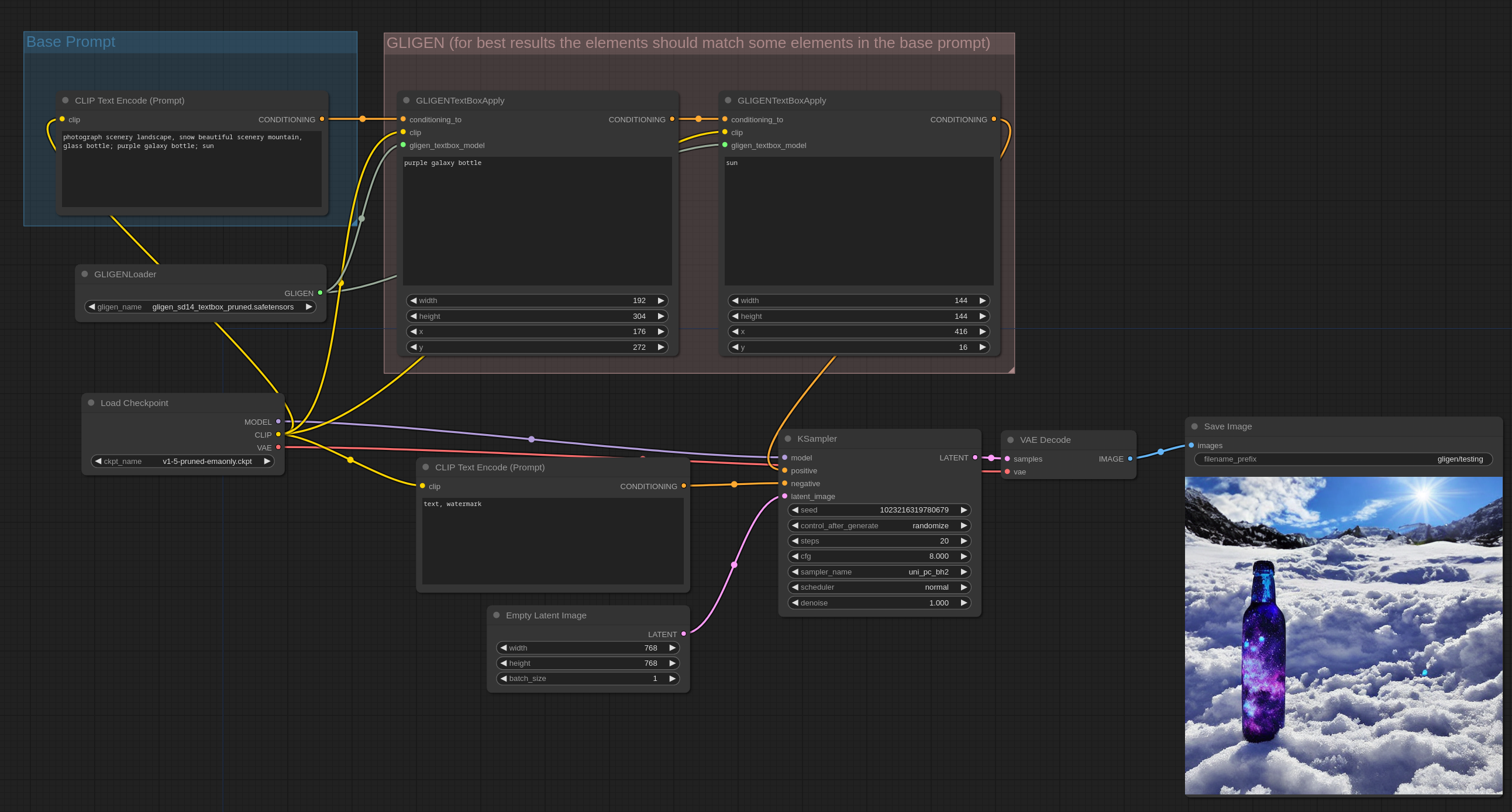
你可以直接把这张图片拖动到 ComfyUI 中来观察完整的 workflow。
12. unCLIP Model Examples
unCLIP 模型是 SD 模型的一种,它被特殊微调过,在文本 prompt 之外,还接受一个图像概念作为输入。图像通过这些模型附带的 CLIPVision 进行编码,然后在抽样的时候,将图像中被提取出来的概念传给主模型。
通俗一点说就是可以在 prompt 中用图像了。
这里是你如何在 ComfyUI 中使用它(还是一样的可以直接拖到 ComfyUI 中查看完整的 workflow)
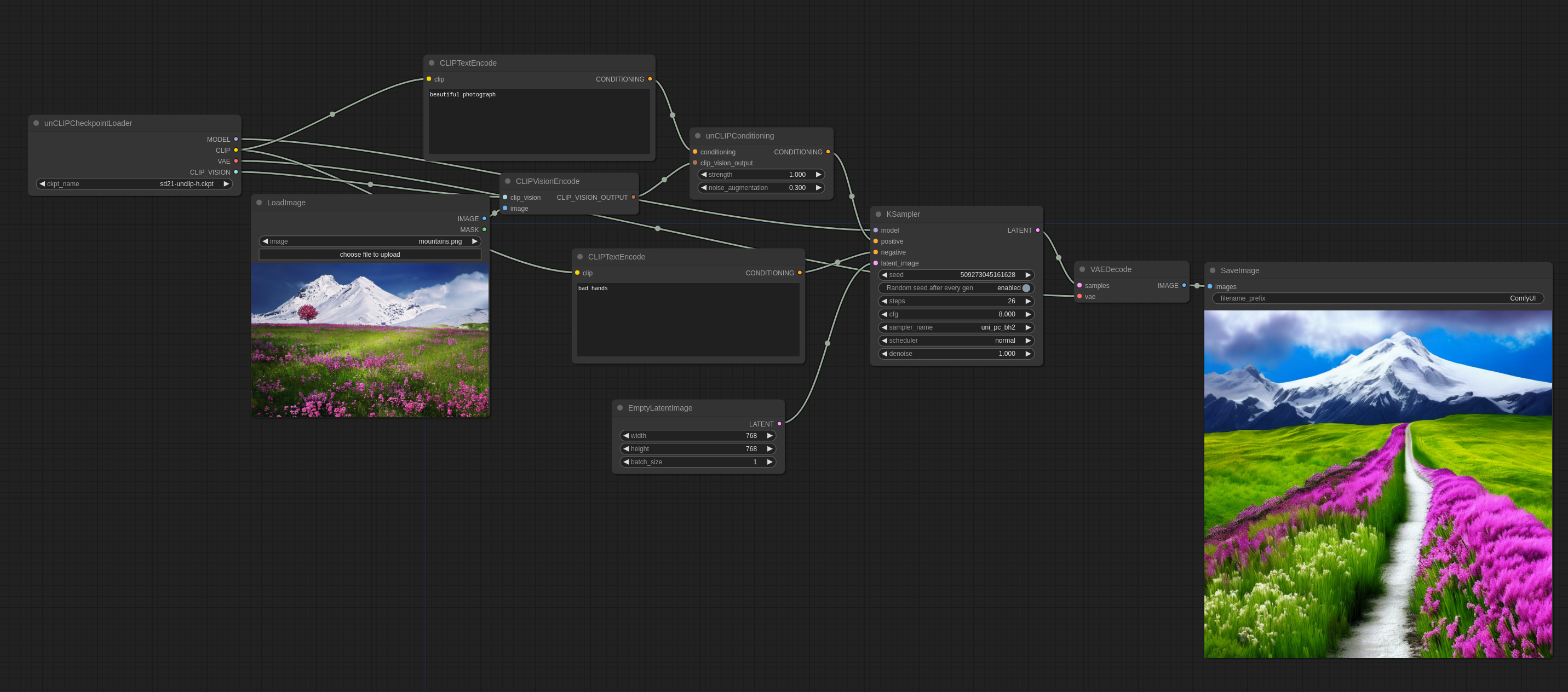
noise_augmentation 参数控制着 unCLIP 模型尝试接近图片概念的程度。参数值越低越接近。
strength 是控制它影响图片的程度。
多个图片可以像这样被一起使用:
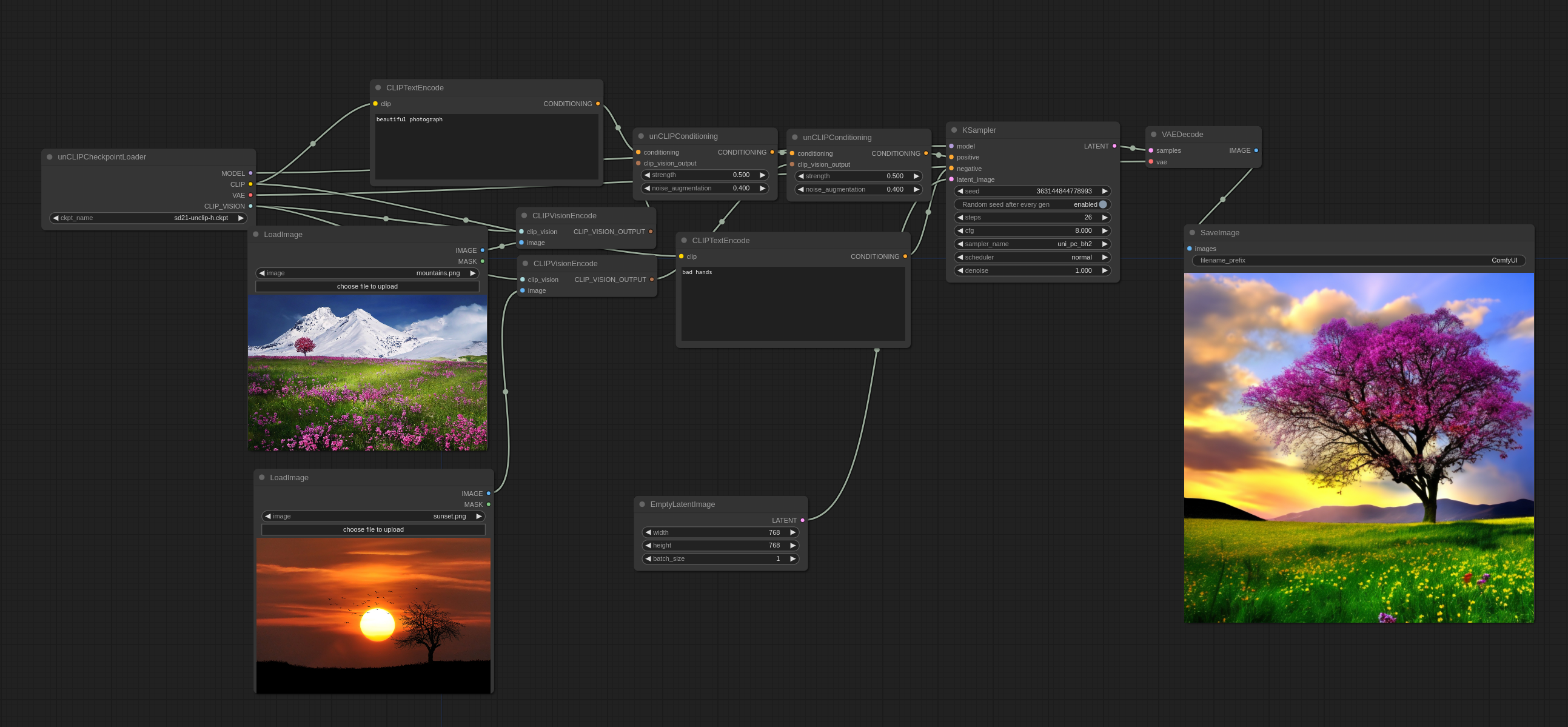
你会注意到它没有用传统的方式将图像直接融合在一起,而是从两者中挑选了一些概念,来创造出一张连贯的图像。
输入图片:


你可以在这里下载官方的 unCLIP 模型。
你可以在这里(基于 WD1.5 beta 2)和这里(基于 Illuminati Diffusion)找到我根据一些现有 768-v 检查点制作的一些 unCLIP 检查点,我还做了一些巧妙的合并。
More advanced Workflows
一个使用 unCLIP 模型的好方法是,在 2 pass workflow 中,在第一道工序中使用 unCLIP 模型,然后在第二道工序中使用 1.x 的模型。下面这张图就是这么生成的。(可以在 ComfyUI 中加载来查看完整的 workflow)

译者:
我猜测是和 Midjourney 的垫图类似,通过先给定一些图片来确定风格,然后再通过 prompt 进行进一步的图片生成。
13. SDXL Examples
SDXL 模型的用法和常规模型的用法是一样的。不过为了获得更好的表现,应该把生成图像的分辨率设置成 1024×1024,或者其他的有着差不多总像素数量的分辨率,比如896×1152或1536×640都不错。
如果要把 base 模型和 refiner 模型一起用,你可以采用这样的 workflow。你可以下载并把这张图拖到 ComfyUI 中来查看完整的 workflow。

你也可以在 base 模型和 refiner 模型上使用不同的 prompt。

ReVision
ReVision 和 unCLIP 很像,但是是在更加“概念化”的层面上工作,你可以传递一张或者多张图片给它,它会从这些图片中提取概念,并使用这些概念作为灵感创造图片。
首先下载 CLIP-G Vison 然后把它放在 ComfyUI/models/clip_vision/ 目录下。
这里是一个示例的 workflow,可以被拖或加载到 ComfyUI 中。在这个例子中,为了能让最终输出尽可能的和输入的接近,text prompt 被 Zero Out (清空)了。
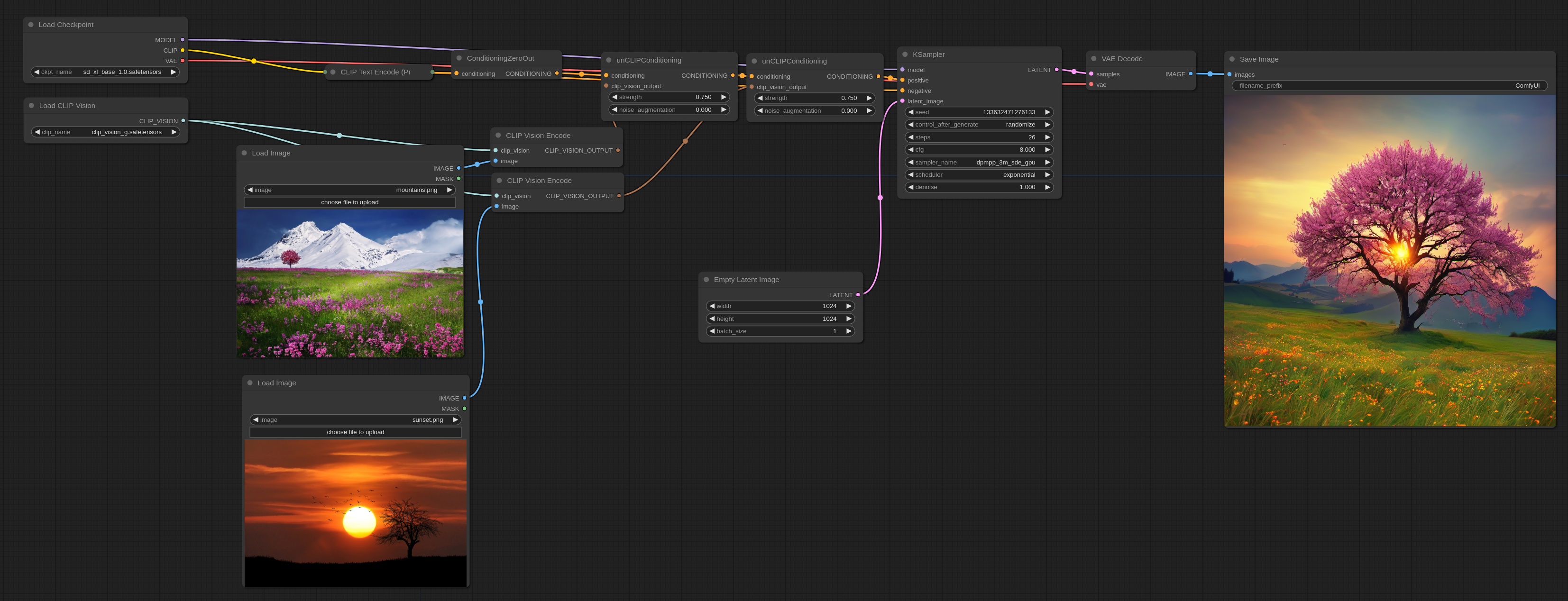
如果你想使用 text prompt 你可以用这个:
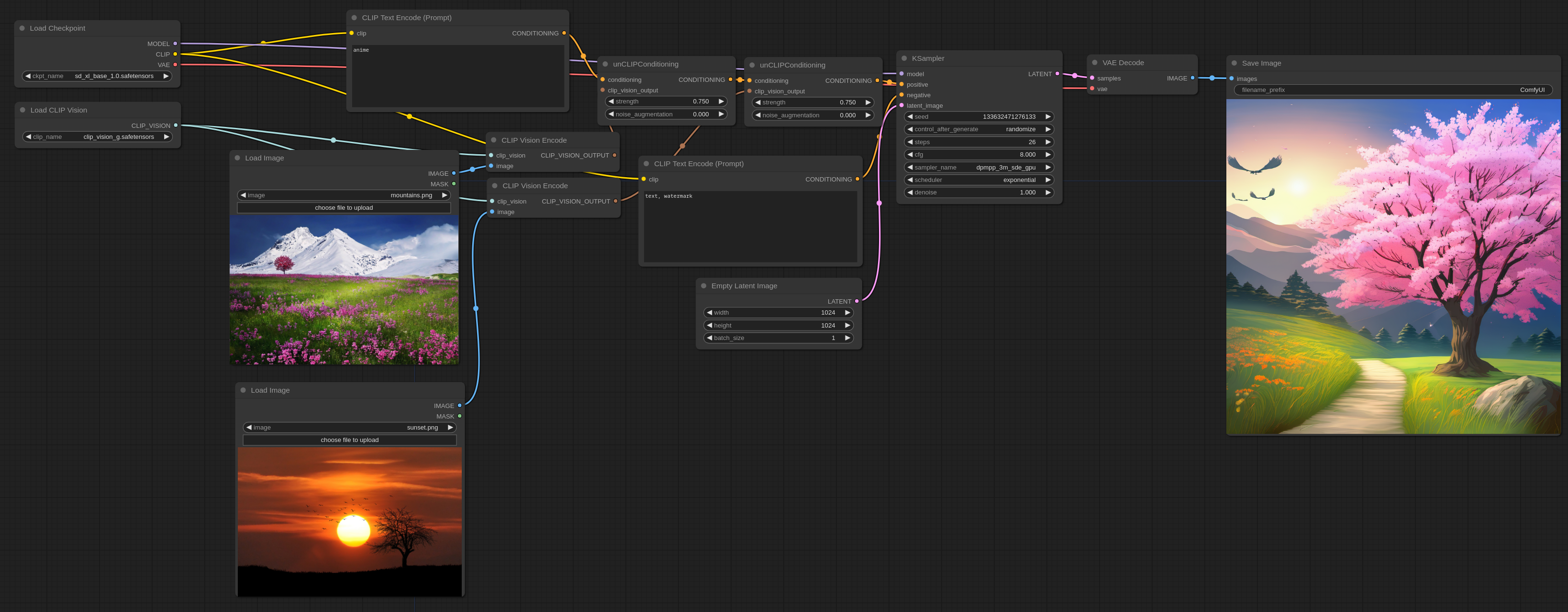
请注意,strength 选项可以用来调整每张输入图像对最终输出的影响。它也可以用在任意数量的图片上,不管是用单一的 unCLIPConditioning 节点还是像上面那样串联起多个节点。
以防万一你需要,这里是用来输入的图片。
14. Model Merging Examples
这些 workflow 背后的想法是,你可以进行一些包含了多个模型合并的复杂的 workflow,对其进行测试,然后一旦你觉得结果满意了,你可以通过启用 CheckpointSave 节点来保存这些 checkpoints(模型的一种)。
你可以在 advanced -> model_merging 这个目录下找到这些节点。
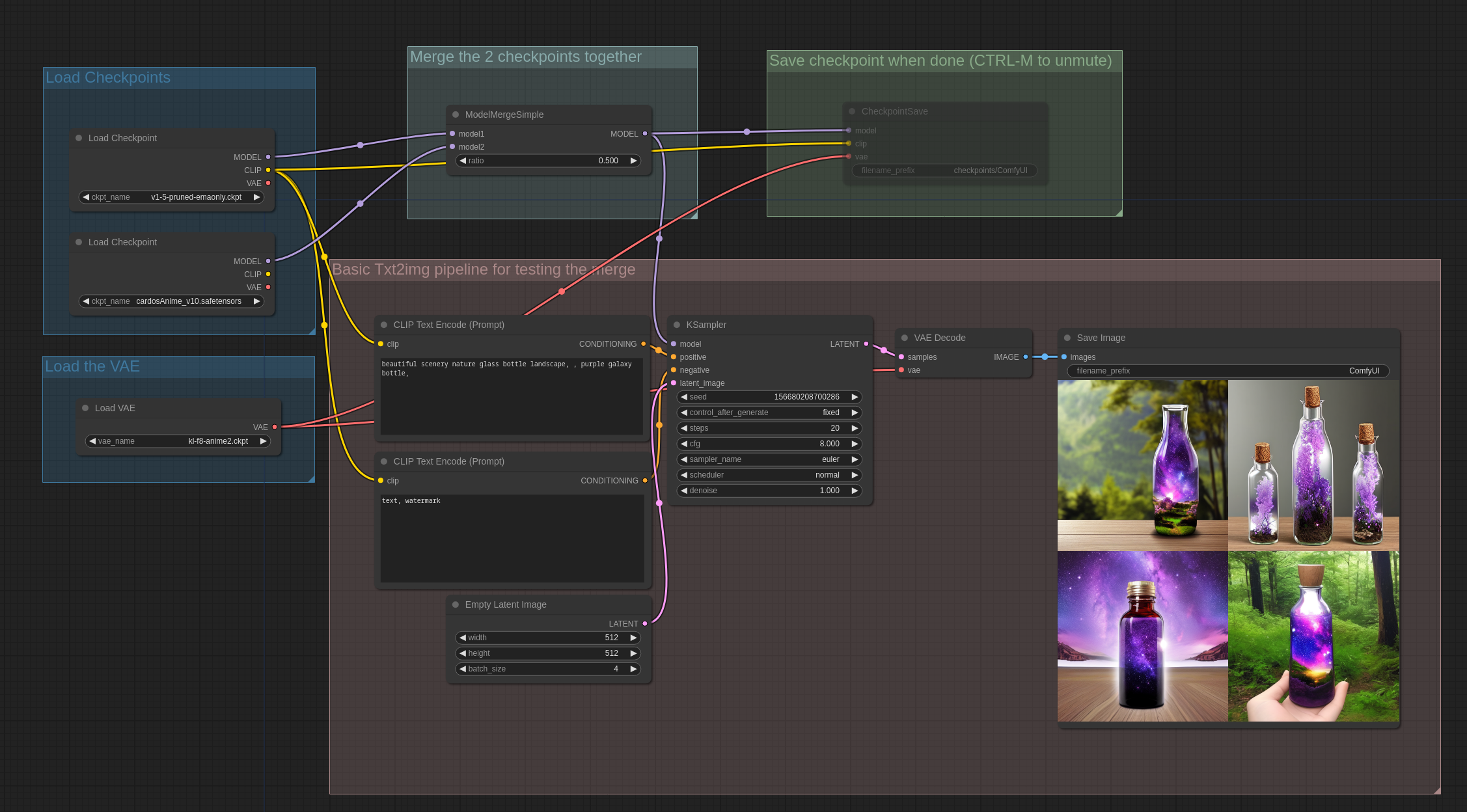
第一个例子是一个基础例子,两个不同模型的简单合并。
你可以通过在 ComfyUI 中加载这些图片来查看完整的 workflow。
在ComfyUI中,保存的 checkpoint 包含了生成它们的完整 workflow,因此它们可以像图像一样被加载到用户界面中,以获取用于创建它们的完整 workflow。
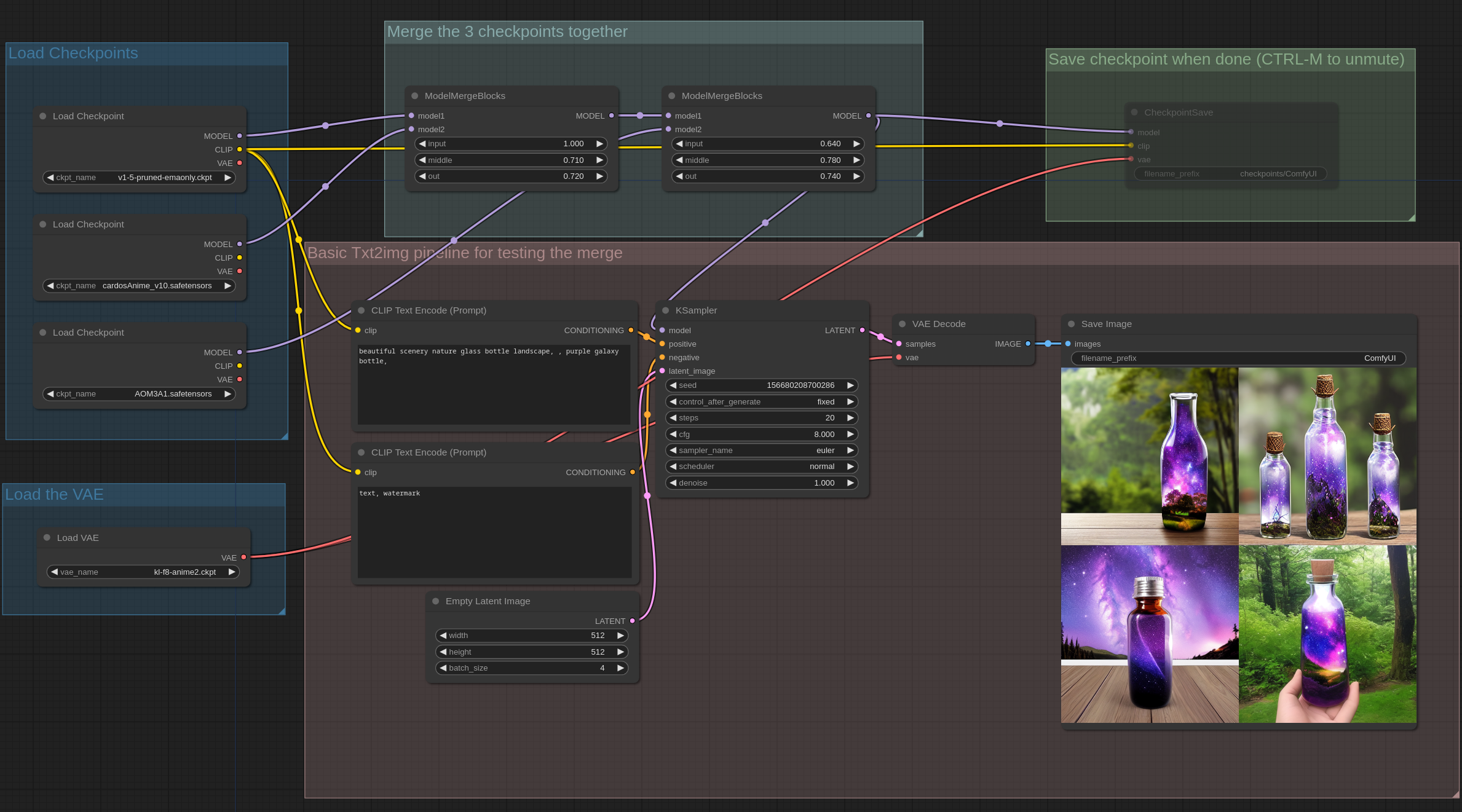
这个示例展示了如何使用简单的块合并来合并三个不同的 checkpoint ,其中 unet 的输入块、中间块和输出块可以有不同的比值:
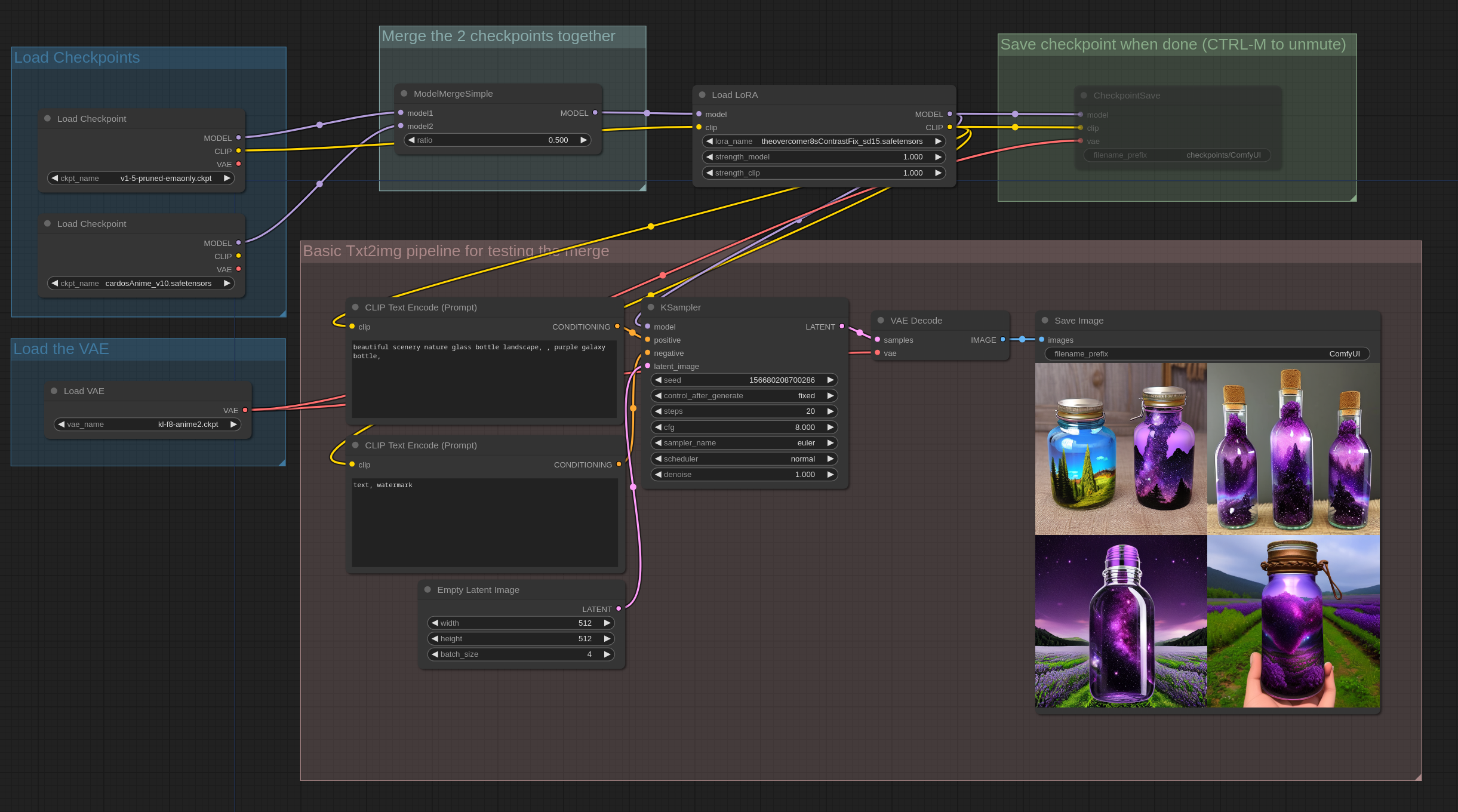
因为 Lora 是一个模型在权重方面的补丁,因此它也可以 merge 到模型中。
你也可以像这个示例一样,减去模型的权重并添加到 merge 中,通常这是用来从非 inpaint 模型中创建一个 inpaint 模型,公式是:(inpaint_model - base_model) * 1.0 + other_model。如果你在其他 UI 中用过“Add Difference”这个功能,在 ComfyUI 中的就是这样实现的。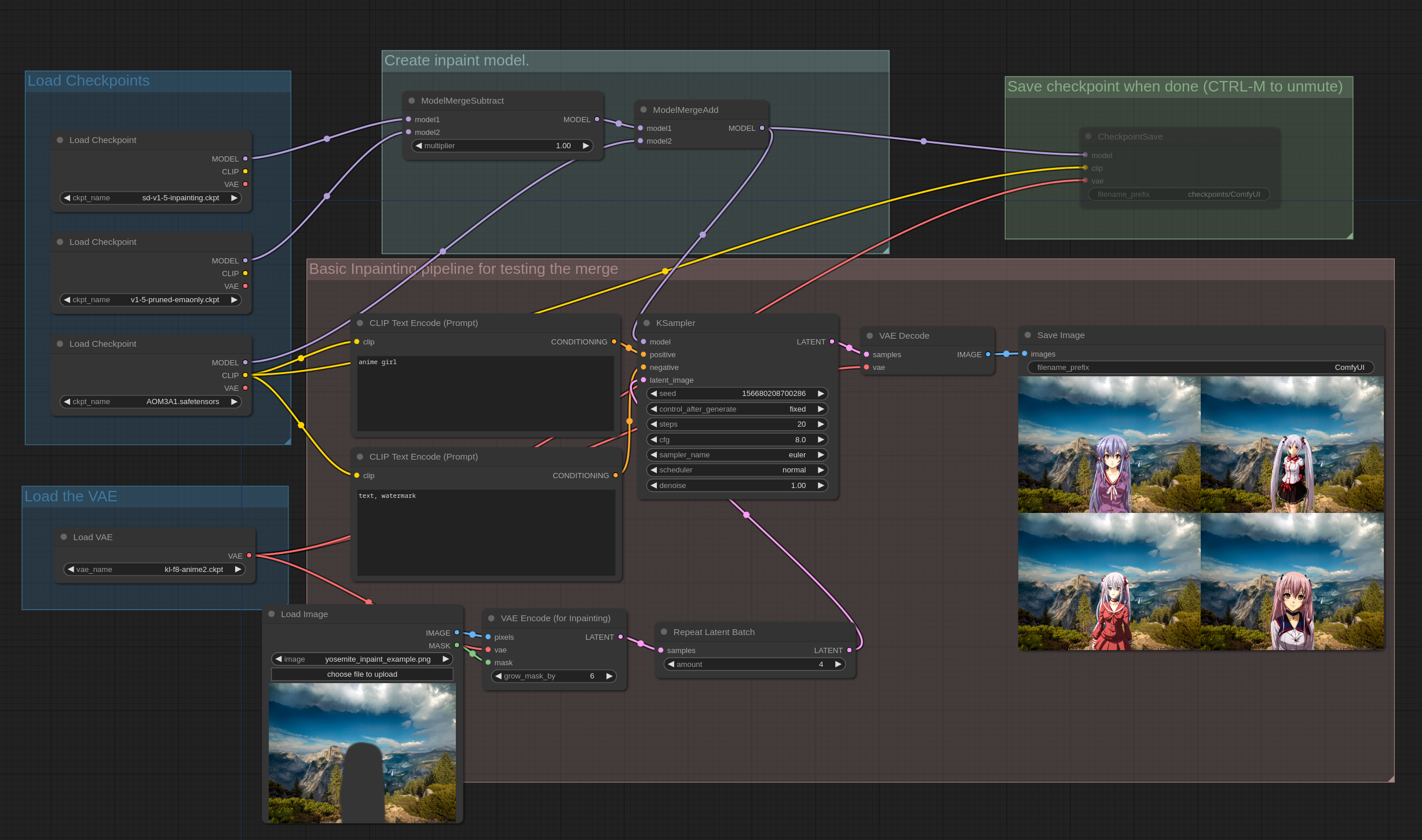
有件重要的事情需要注意,模型的合并保存,一般会用你硬件上推理用而设置的精度,也就是 16位浮点数,如果你想以 32 位浮点数进行合并,请使用以下命令启动 ComfyUI:--force-fp32
Advanced Merging
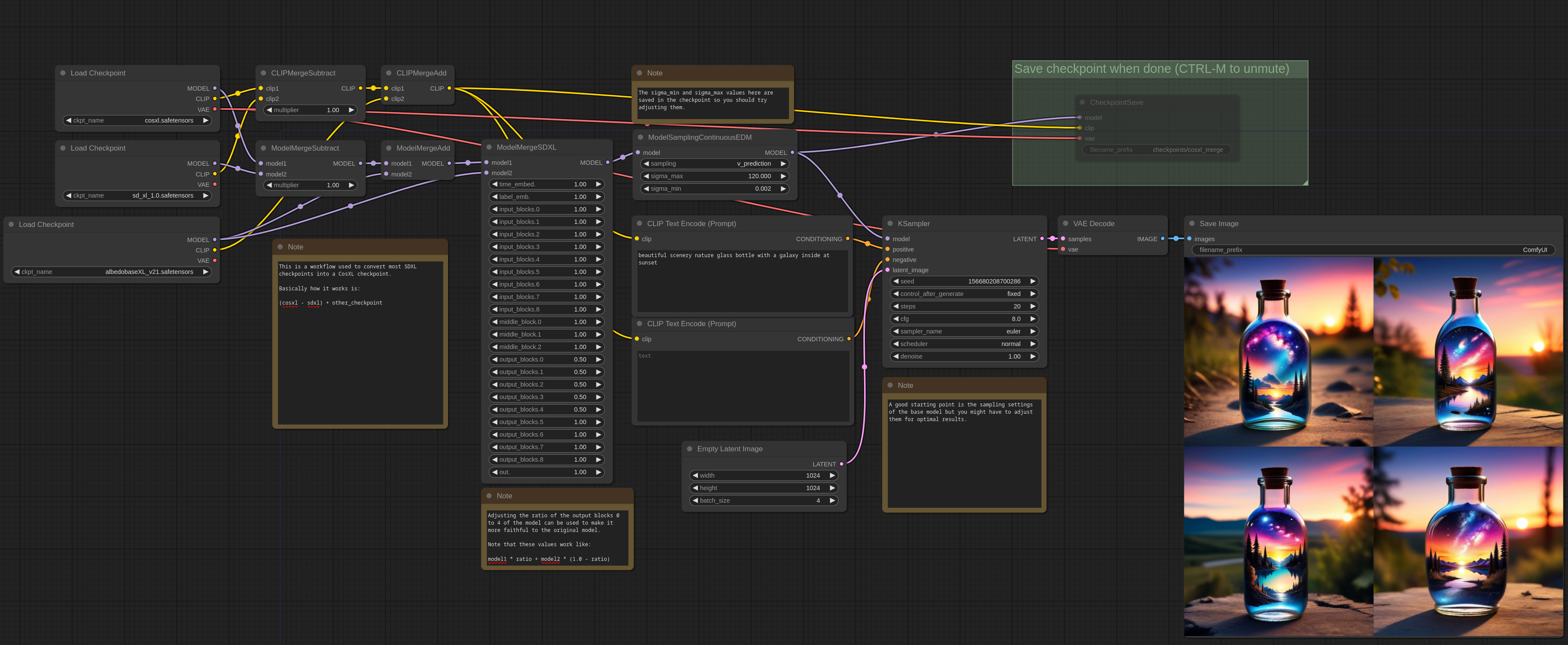
CosXL
这里是一个如何通过合并从常规 SDXL 模型创建 CosXL 模型的示例。所需的是 CosXL 基础模型、SDXL 基础模型以及你想要转换的 SDXL 模型。在这个示例中,我使用了albedobase-xl。
15. 3D Examples
Stable Zero123
Stable Zero123 模型能够根据带有物体和简单背景的图像,生成该物体从不同角度的图像。
下载模型后把它放在 ComfyUI/models/checkpoints 文件夹。
你可以下载下面这张图然后把它放在 ComfyUI 中来获得完整的 workflow。
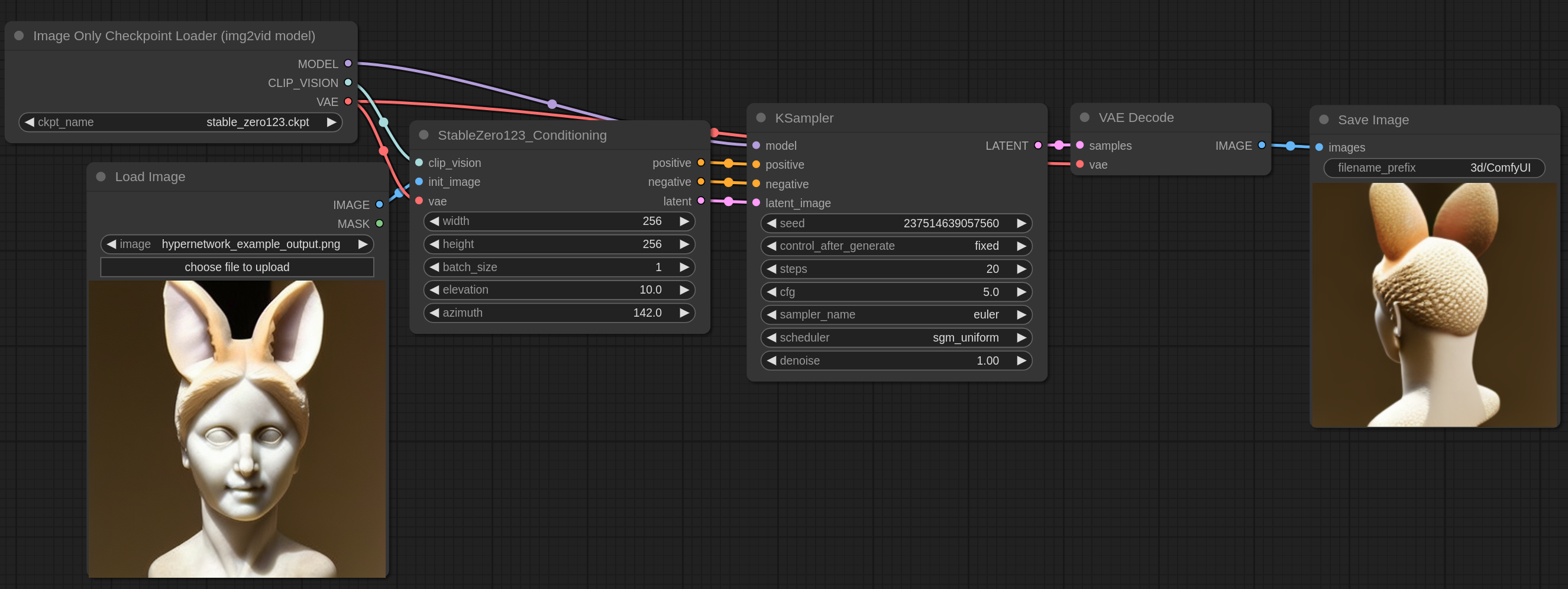
输入图像可以在这里找到,它是来自 hypernetworks example 的输出图像。
Elevation(俯仰角)和 azimuth(方位角) 以度为单位,用来控制物体的旋转。
16. LCM Examples
LCM 是被设计成用少量步骤进行采样的模型。
LCM Loras 可以用来将普通模型转换成 LCM 模型
LCM SDXL lora 可以在这里下载到
下载后重命名成 lcm_lora_sdxl.safetensors ,然后放在 ComfyUI/models/loras 目录下。
然后你可以在 ComfyUI 中加载这种图像来查看将 LCM SDXL lora 和 SDXL 基础模型一起使用的 workflow:

需要注意要使用比较低的 cfg 值,使用 “lcm” 采样器,以及”sgm_uniform”或”simple”调度器。带有 lcm 设置的 ModelSamplingDiscrete 节点也会稍微改善效果,虽然不是必要的,但也推荐使用。
其他的 LCM loras 也可以用相同的方式用在各自对应的模型上。
17. SDXL Turbo Examples
SDXL Turbo 是 SDXL 模型的一种,可以在单步中生成 consistent 的图像。你可以用更多的步骤来增加生成的质量。比如用新的 SDTurboScheduler 节点效果会比较好,但是常规的调度器也行。
这是下载官方 SDXL turbo 模型的地址
这是用对应的 workflow 生成的图片:

把这张图像保存下来并拖到 ComfyUI 上来查看完整的 workflow。然后我推荐在界面中启用 Extra Options -> Auto Queue。然后点击 “Queue Prompt” 并开始编写你的 prompt。
18. Stable Cascade Examples
首先下载 stable_cascade_stage_c.safetensors 和 stable_cascade_stage_b.safetensors checkpoints 放到 ComfyUI/models/checkpoints 文件夹中。
Stable cascade 是一个有三个阶段的处理流程,首先是用 C 阶段扩散模型生成低分辨率的 latent 图像。然后在 B 阶段扩散模型中放大它。放大后的图像再次放大后,通过 A 阶段的 VAE 转换成像素图片。
你可以下载本页面中的所有图像,然后加载或拖到 ComfyUI 上来查看完整的工作流程。
Text to image
这是一个基础的文生图 workflow

Image to Image
这里是一个基础图生图的例子,通过编码图片然后传给阶段 C 来实现。

Image Variations
Stable Cascade 支持使用 CLIP vision 输出来创建图像的变体。请参考以下示例工作流程:

下面这个工作流展示了应该如何把多张图片混合到一起:

你可以在 unCLIP example page 找到用来输入的图片。
ControlNet
你可以从这里下载 stable cascade 用的 controlnet。在这些示例中,我通过在文件名前添加stable_cascade_来重命名文件,例如:stable_cascade_canny.safetensors、stable_cascade_inpainting.safetensors
下面是一个如何使用 Canny Controlnet 的示例:

下面是一个如何使用 Inpaint Controlnet 的示例,示例输入图像可以在这里找到。你还可以在 LoadImage 节点中右键点击图像,并使用遮罩编辑器对其进行编辑。

19. Image Edit Model Examples
Edit 模型,也成为 InstructPix2Pix 模型,是可以通过文本提示编辑图像的模型。
这是 SDXL Edit 模型的 workflow,可以在这里下载模型。下载 cosxl_edit.safetensors 文件后,将其放在 ComfyUI/models/checkpoints 文件夹中来使用它。

把这张图像保存下来并拖到 ComfyUI 上来查看完整的 workflow。
上述示例中使用的输入图像可以在这里下载。
20. Video Examples
Image to Video
目前有两个将图片转换成视频的模型。the one tuned to generate 14 frame videos 和 the one for 25 frame videos。下载后放在 ComfyUI/models/checkpoints 文件夹中。
最基础的使用图生视频功能的方式是,输入一张初始图片——就和下面的这张一样——然后使用 14 frame 模型。你可以下载这张 webp 格式的动画图片,然后加载或直接拖到 ComfyUI 中来查看完整的 workflow。

你可以在 unCLIP example page 里找到输入图片。
你也可以在下面这个 workflow 里使用这个功能,它用 SDXL 模型来生成一张初始图片,然后传递给 25 frame videos:

关于参数的一些解释:
video_frames:要生成的视频帧数。
motion_bucket_id:该数字越高,视频中的动态部分越多。
fps:帧率越高,视频越流畅。
augmentation level:添加到初始图片的噪点数量,该值越高,视频与初始图片的相似度越低。增加该值可获得更多的动态效果。
VideoLinearCFGGuidance:这个节点稍微改善了这些视频模型的采样效果,它的作用是在不同帧之间线性缩放 cfg。在上述示例中,第一帧的 cfg 为 1.0(节点中的 min_cfg),中间帧为 1.75,最后一帧为 2.5(采样器中设置的 cfg)。这样,离初始帧较远的帧将逐渐获得更高的 cfg。
ComfyUI_examples 翻译笔记