炜哥的AI学习笔记——主流模型原理
这次对目前主流的一些模型原理进行介绍,也就是 C 站目前比较常见的这几种模型。
这个文章会更偏向于讲述这些模型之间的区别,训练方式也会稍微带一下,不过不会很具体。
前置知识
在阅读这篇文章之间,需要先对 Stable Diffusion 有一定的了解。建议不熟悉的人先去阅读SD基础原理这一片文章。
我也先把这一个流程图放在这里,方便后续对照着进行理解。
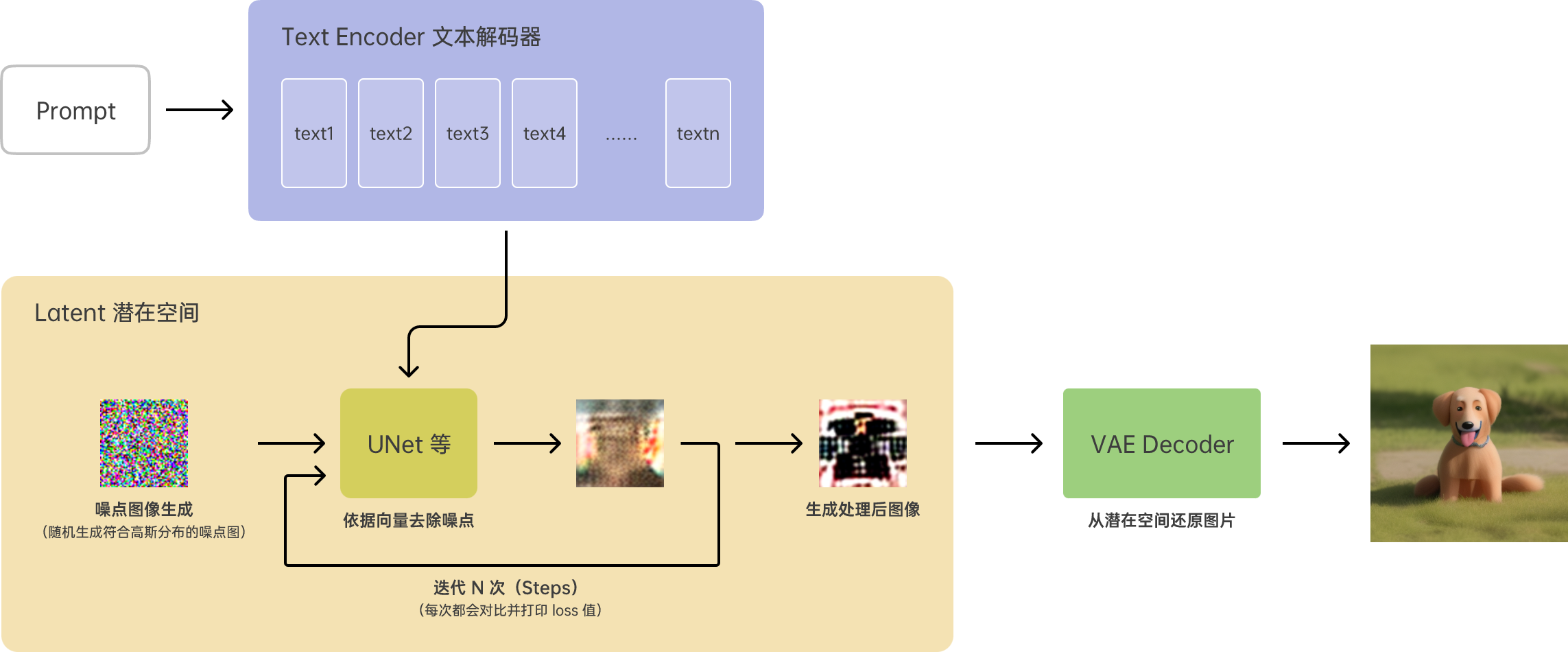
(实际结构会复杂很多,这里使用相对易于理解的方式对流程进行拆解)
如果是使用默认的 SD 模型进行图片生成,就是上面这条路子。
简单的说一遍就是:通过 Text Encoder 把输入的 Prompt 根据词典解码成文本向量,然后在 UNet 中作用文本向量,从随机生成的噪点图像中根据文本向量按照一定规则去除噪点,迭代 N 次后就在潜在空间中生成了对应的图片,这时再通过 VAE 将图片从潜在控件中还原成适合使用的图片。
而不同模型对于这套流程的影响,会作用在不同的位置上。
三种主流模型
Checkpoint
首先是 Checkpoint,也就是俗称的大模型。但是其实这个名称并不准确,因为 Checkpoint 并不是完全从零开始的大模型,从零开始的大模型需要非常多的数据量以及训练量,所以 Checkpoint 也是在现有的模型基础上训练而来的,一般会选择使用原始的 SD 官方模型,也有基于其他成熟模型二次训练的模型。
而 Checkpoint 这种模型,作用的主要是 Text Encoder 和 UNet 为主的噪点处理相关的模块。
还是用一个具体的例子来说明,Checkpoint 目前的主要训练方式是使用 Dreambooth ,Stable Diffusion 有对应的插件,或者也可以像我一样使用 Kohya_ss 进行训练。
这里按照 Kohya 官方的教程,我训练一个青蛙的概念。

对于这种特殊的青蛙,我取名叫做 sls 。后面 空格+frog 是对类别的描述,一般是使用了正则化图像训练的时候才会用到的,这里不展开了,关键还是 sls 这个特殊词语。这个词语不是现有的英语单词,而是我造出来的一个词语,我希望教给 AI 的是,现在训练集里的这种青蛙名字就叫做 sls,这样在使用训练完成的模型后,我输入 sls 就可以让 AI 生成这样的青蛙图片了。
训练过程就不展开了。不过为了避免误导我还是多说一句,这种方式只是 Checkpoint 的一种训练方法,Checkpoint 也是可以通过打标然后使用标签进行训练的(目前常用的 LoRA 训练方法就是这样),具体可以看 Kohya 官方的教程。
言归正传,其实抽象出来看事物,我希望 AI 学会画训练集中的这种青蛙,而在训练过程中教给 AI 的就是两件事,第一件事是 sls 这个“新词语”,第二件事就是这种特殊青蛙的“概念”。而这两件事对应也就是 Text Encoder 和 UNet,这也就是训练完成后的模型相比原模型不一样的地方了。
Text Encoder 里面有一本“词典”,这个“词典”记录了所有文本的向量信息。当输入 Prompt 后,Text Encoder 里面的字典会根据“词典”编码出对应的文本向量,而向量又和图像特征关联,最后输出给 UNet。那么当输入一个新的词语,比如 sls 时,因为这个词语在“词典”里没有,所以就会新增一套不同的文本向量。所以让 AI 学习概念的时候,一般使用自己造的词语来固化这个概念,如果是熟悉的词语 Text Encoder 就会选择使用其他的文本向量来理解这个词语,就会污染到其他的文本向量。
这就是训练出来的 Checkpoint 模型的一部分,在原 Checkpoint “词典”的基础上增加了一些新“词”。
UNet 部分。这个模型现在含有了 sls 的“意思”,也就是可以让使用这个模型的 AI 知道 sls 是什么意思,那么接下来就是第二件事要教会 AI 怎么去画特殊青蛙。AI 画图的方式是使用 UNet 逐步迭代去噪点,那么训练出来的模型就是在原模型的基础上增加了对于特殊青蛙这一部分的学习,让 AI 知道用什么方式去噪点可以呈现出这种特殊青蛙的样式。
如果用一种比较生动的比喻来说的话,每个模型就是一个画家,训练 Checkpoint 的过程就是把官方提供的“通用型”画家,复制一份,然后教会他“什么是 sls 青蛙”,“怎么画特殊青蛙”。
然后这么理解之后,其实也就很好理解 Checkpoint 的特点了。它是把官方“通用型”画家复制了一份然后学习的,所以是比较纯粹的(当然更纯粹的是从零开始训练模型不过基本上这就告别了家用电脑的可能),训练的效果会比较好。但是,因为是复制了整个画家,所以模型的体积也会比较大,基本都是几个 G 起步,同时对于显存\运算能力的要求也比较高。
Textual Inversion
和 Checkpoint 不同,Textual Inversion(以下简称 TI)只影响 Text Encoder 部分,更精确点说应该是影响里面的那本“词典”。它的思想是这样的,就是:希望教给 AI 的概念可以用现成的词语进行描述。
还是以上图的 sls 举例,这个 sls 青蛙,是不是可以用普通的 frog,还有 illustration ,还有 cartoon ,等等这些词语的词向量组合来描述呢?听起来似乎有些不可思议,但是实际它的确成功了。当然实际的训练过程比我提到的例子还会复杂数倍,或者说把它理解成一种对于“词典”中内容的重新排布会更加合适。
 模型的特点也是显而易见的,首先它只是对于“词典”进行改动,所以文件非常非常小,基本上是以 KB 为单位的。不过使用的时候需要搭配 Checkpoint 进行使用,可以理解成对于 Checkpoint 里的“词典”部分进行了加强。
模型的特点也是显而易见的,首先它只是对于“词典”进行改动,所以文件非常非常小,基本上是以 KB 为单位的。不过使用的时候需要搭配 Checkpoint 进行使用,可以理解成对于 Checkpoint 里的“词典”部分进行了加强。
然后它的效果,虽然我并不是很常使用这种模型,不过根据网络上使用 TI 的作品来看,TI 更多是起到“改善”的作用,对于概念的学习效果比较有限。这应该也很好理解,毕竟只是改动了“词典”,“画家”的绘图本领还没有进化。
LoRA
LoRA 应该是最近最火的模型种类了。虽然说 Checkpoint 这种模型的训练方式相比从零开始训练,节约了很多的时间和算力,让家用电脑也能参与到模型训练这件事情上来,但是训练大模型所需要的硬件要求还是很高。这个时候有人就在想,相比于完全复制一个现成模型进行训练,是否可以单独训练模型的一部分,然后将这部分和原模型进行合并使用呢?似乎就可以进一步降低模型训练所需要的资源了。
所以,Low-Rank Adaptation 技术,也就是 LoRA 就出现了。我之前在 SuperMerger的用法这篇文章中讲过,Checkpoint 中一共有 26 个分层,而需要 AI 学习的概念就在这 26 个分层中。但并不是所有的分层都和概念的学习紧密相关,LoRA 就是在其中一些分层中再加入额外的一些东西,去调整其中的几个层。
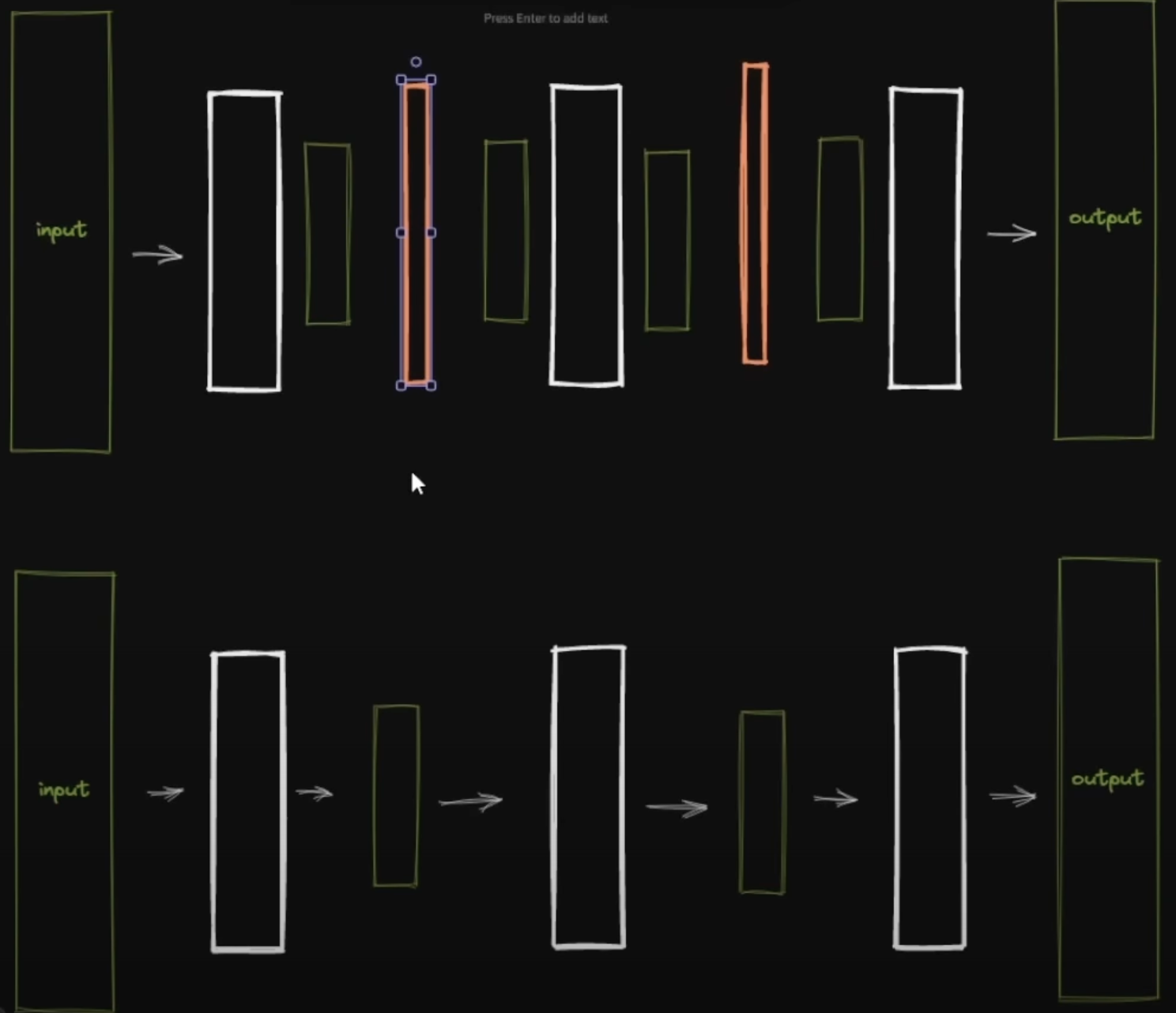
下半张图是正常的 Checkpoint 模型,一层一层传递信息,而上半张图红色部分则是 LoRA ,在原模型的一些层中插入了额外的层,去控制这些层所学到概念。在训练 LoRA 的时候就是训练这部分的内容,间接的控制出图的效果。
还是以”画家“距离,Checkpoint 是完全复制的一个画家,教他新的概念,LoRA 则是选择在这个画家的脑子里加入一些东西,就好像画外音一样,告诉画家要怎么画。
当然对于 Text Encoder 的学习也是有的,不过和 Checkpoint 一样,这里就不多讲了。
总之,相比于完全使用 Checkpoint 进行学习,LoRA 需要学习的内容更少,但是效果却不比大模型差。而因为耗费的资源相比 Checkpoint 大大减少了,所以也有更多的人参与进来,C 站上也出现越来越多的优质 LoRA 模型。
同样的 LoRA 和 TI 一样是在 Checkpoint 基础上的训练,所以也需要搭配 Checkpoint 模型使用。
其他模型
HypernetWork
和 LoRA 一样,也是在 Checkpoint 的不同层里动手脚,不过稍微有些区别的是,HypernetWork 单独分出了一个模块用来做这个事,实际训练的过程中,是在训练这个外在模块,然后这个模块再生成一些额外层到 Checkpoint 的层里去。相对来说有一些多此一举,所以目前在 LoRA 推出之后,很少有人再训练 HypernetWork 了。
LyCORIS
严格来说也是 LoRA 的一种,之前在 [Lock-block-weight](https://xuweinan.com/2023/06/13/炜哥的AI学习笔记——Lora-Block-Weight 插件学习/) 中应该有提到过,相比于 LoRA 的17层结构,LyCORIS 有 26 层,也就是对 Checkpoint 每一次都插入了额外的东西,可以算是 LoRA 的进阶版本。不过多层的话,后面调整起来也会复杂一些,对于精细度要求不那么高的 LoRA ,17 层已经能满足。
参考资料
https://www.zhihu.com/question/588685139
https://github.com/bmaltais/kohya_ss/blob/master/train_db_README.md
炜哥的AI学习笔记——主流模型原理