炜哥的AI学习笔记——SD基础原理
在深入学习其他技术知识之前,我觉得还是有必要了解一下 Stable Diffusion 的基础原理是什么样的,不然后面参数太多了,一个一个参数如果是很零散的方式去记忆的话很容易就忘光,所以还是需要有一条线串起来。
Diffusion Model
Stable Diffusion、Midjourney(尚未开源但是可以从图片生成的过程中推测) 以及现在网上流行的一堆 AI 图片生成算法,基本上都依赖于 Diffusion Model 扩散模型,其核心思想是从一张充满了噪声的图片中,还原出具有特定元素的图片。

这个过程中,主要涉及到两个部分的模块,基于 CLIP 的文本编码器 Text Encoder,负责噪声处理的的 U-Net 。
在训练模型,调参的过程中,也经常会去设置这两个参数。以我常用的 Kohya_ss 为例,就支持在训练时单独设置 Text Encoder 的学习率和 Unet 的学习率。

当然这个学习率的调整讲起来又是复杂的一节课,这里先不展开了。
图片生成过程
这在这个两个核心模块的作用下,Diffusion Model 的图片生成过程可以这么理解:
第一步 噪声图片生成
Stable Diffusion 的模型生成,都是从一张随机噪点的图片开始。而这张噪点图片,是通过 Seed 值,也就是我们平时使用 Stable Diffusion 中的 Seed 生成的。
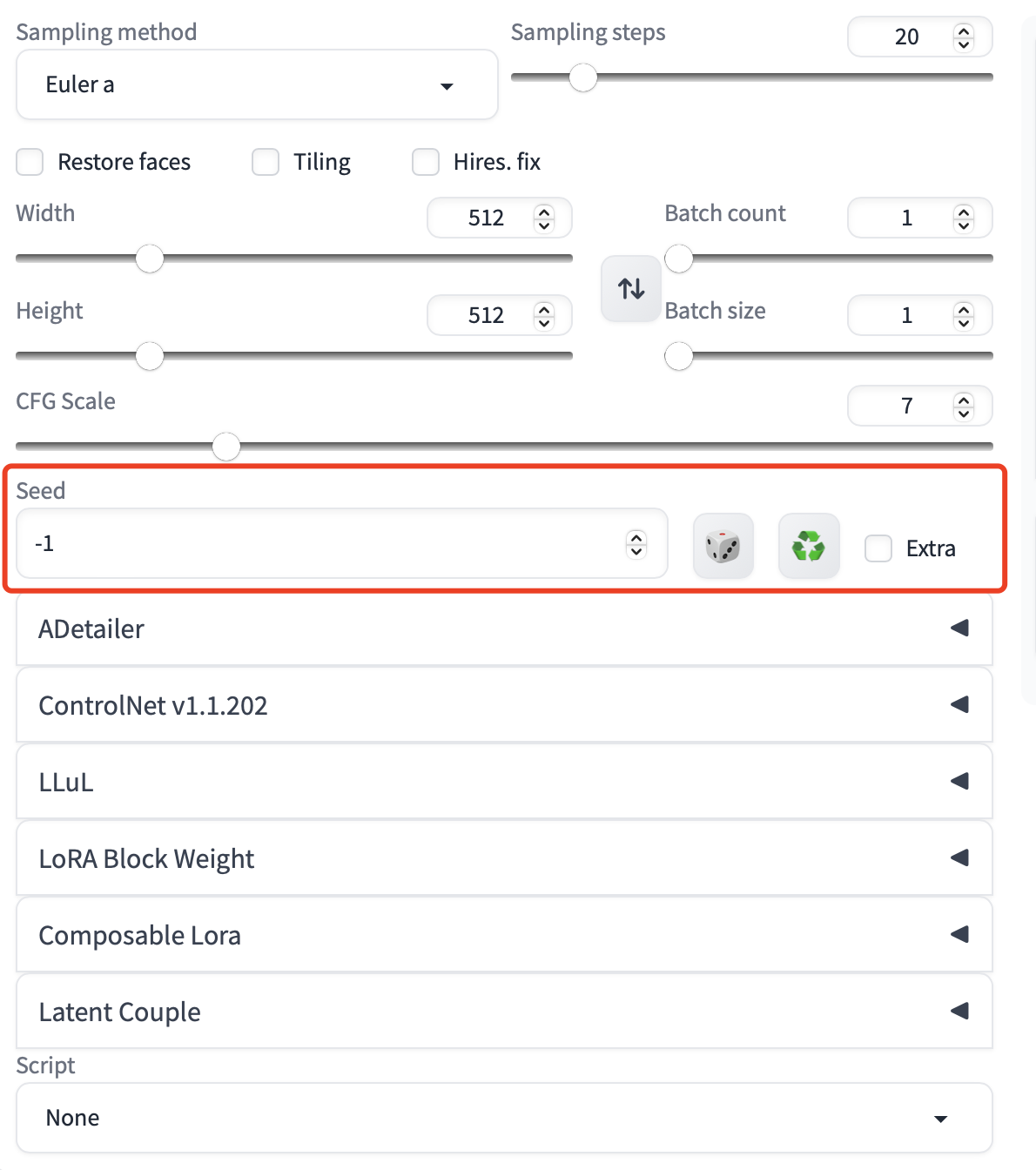
所以如果将这个值固定,也就意味着一开始生成的初始噪声图片都是固定的的,那么在相同的 Prompt 和模型的作用下,生成出来的图片也会大差不差。在一些特殊的场景,比如调试 Prompt、测试插件,经常会使用这个特性来对比前后生成的图片。
第二步 理解 Prompt
有了一张完全噪声的图片,接下来要做的事情就是理解 Prompt,而这个就是 Text Encoder 的工作。
这里又可以分为两块来讲,特征学习和向量化。
特征学习,就是将大量成对的文本和图片输入到机器学习中,让 AI 学习到文本特征和图片特征之间的关联,最终生成模型。
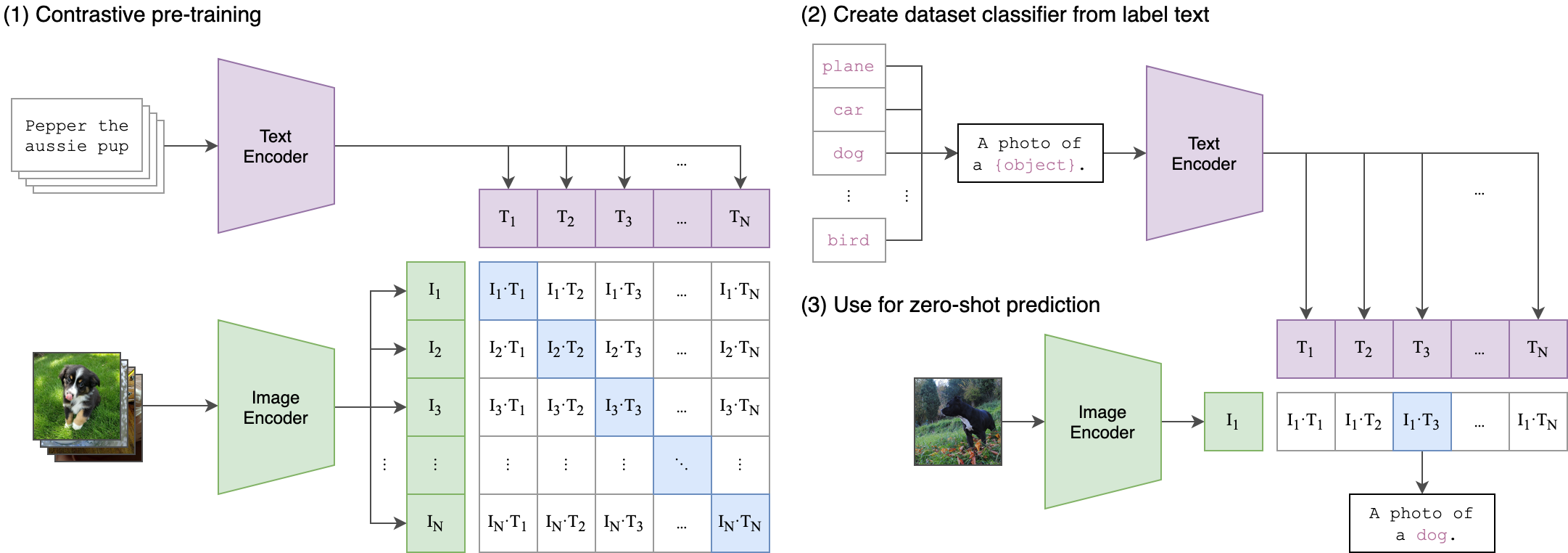
这一部分的训练方式就叫做 CLIP ,全称 Contrastive Language-Image Pre-Training,对比语言图像预训练。当然这种数据量是非常巨大的,Stable Diffusion 也是使用了 OpenAI 训练好的现有模型来理解 Prompt 。
所以在一开始安装 Stable Diffusion 的时候,会下载 clip 和 openclip 这两个github上的代码仓库。(因为 openai 原始 clip 虽然算法开源了,但是训练集没有开源,因此后续版本 Stable Diffusion 使用了开源的 openclip 版本,所以这里两个都下载)
然后这里其实还有一个特别重要的技术,虽然也是 CLIP 的一部分,但是我觉得这有利于理解 Prompt 的使用机制所以还是单独拿出来,就是向量化。
如果只是将世界上所有的文本和图像进行特征配对,虽然能实现,但是需要的运算量是巨大的,CLIP 最开始的模型是在 4 亿多个图像/文本对上训练的,用了 256 个 GPU 训练了两周。这显然并不利于后续的维护和升级,而且普通的开发者难以参与。
因此向量化这个想法出现了。为了理解向量化,我这里还是举一个比较经典的例子:如 AI 知道 king 这个单词的意思,我们要如何去教会它 queen 这个词的意思呢?答案是当这两个词语都被转换为向量的时候,queen 就可以等同于 king-man+woman 的向量运算。通过将平时我们使用的语义词汇,转变成数学计算的方式,大量的词语就被联系起来了,从而减少了模型训练中词汇的使用。而图片也是同理的,图片的特征同样可以被向量化,不过这里不好举例子。
有兴趣的可以详细去了解 ViT 模型和 Transformer 模型,前者能将图像转换为向量,后者则是将文本转换为向量。或者,直接官方的 CLIP 论文或开源项目地址。
第三步 图片降噪
在 Prompts 被模型理解之后,就是一个降噪的过程,U-Net 网络结构会进行不断地迭代,每一次迭代都去除一部分的噪声。

(因为 VAE 的关系,过程图不会出现肉眼可见的噪点,至于 VAE 的作用一会再讲)
在每次去除噪声的过程中,还会使用一种叫做“Classifier Free Guidance”的方法去强化和 Prompts 相关的噪声,直到完全还原元素。而这个方法的缩写 CFG 也就是 WebUI 中的 CFG scale 值,即强化的倍数。因此不难理解为何一堆速成教程中都提到这个值和 Prompt 的关联度强相关,以及调整过头为什么会导致图片结构变形。

U-Net 是怎么降噪的?
降噪过程本质也是一种机器学习,就和 CLIP 关联图片和文本特征。这一块并不复杂,倒是可以细讲一下。
机器学习的本质就是找规律,如何从一堆噪声中找到需要去除的噪声,就是机器学习要找到的规律。而这一过程就是训练,训练的流程和上面提到的图片生成的过程相反,图片生成是去噪,那么训练图片就是加噪声。
对于一张已有图片,对它一步一步的加上噪声,并在每一步进行深度学习,这样 AI 就有能力理解在不断增加噪声的过程中,更好的学习到图像的特征。

然后这种步骤重复上千上万次,AI 就可以从其中找到规律,知道如何根据 Prompts 将噪声逐渐还原到对应的图片。而这一部分的“经验”(实质上是一堆复杂函数)就被作为模型文件保存下来,也就是我们经常看到的 checkpoint 等模型文件。
LDM 模型与 VAE
除了基础的扩散模型,还需要讲清楚一个新的模型 LDM,也就是 Latent Diffusion Model,潜在扩散模型。
去年年底 Stable Diffusion 开始爆发式增长,有一个很重要的原因就是训练工具的平民化。从刚才的描述中应该也不难意识到,无论是模型的训练还是使用,都需要大量的迭代,大量的运算来寻找或者是还原规律,个人的计算机设备几乎无法支撑这这一块的算力。所以之前的训练注定只能在大公司或者研究机构中进行。
这个模型的核心思想是,造成 AI 绘图需要巨大算力的关键原因,还是图片像素的数量太多了。那么既然如此,将图片缩小是否就可以解决这个问题呢?比如说将一张 512×512 的图片缩小成 64×64 的图片,理论上需要的算力会减少 64 倍,那么这种压缩后的图片是否还能用于训练呢?
答案是可以的。先说训练过程的不同,相比于之前直接将原图添加噪点训练,LDM 先将原图用一种方式“压缩”,压缩后的图片所在的位置就叫做“潜在空间”,这也是 LDM 中 Latent 所代表的意思。当图片被压缩到了潜在空间后,训练需要的算力和时间就被大大减少,但是却不会损失多少训练所需要的图片特征。
而使用 AI 生成图片的过程也是一样的,先从随机种子种生成“潜在空间“的随机噪声图片,然后就和训练的逆过程一样,在”潜在空间“里完成对噪声图片的还原,最后再把还原后的图片从”潜在空间“里拿出来,把图片反”压缩“回正常的图片。
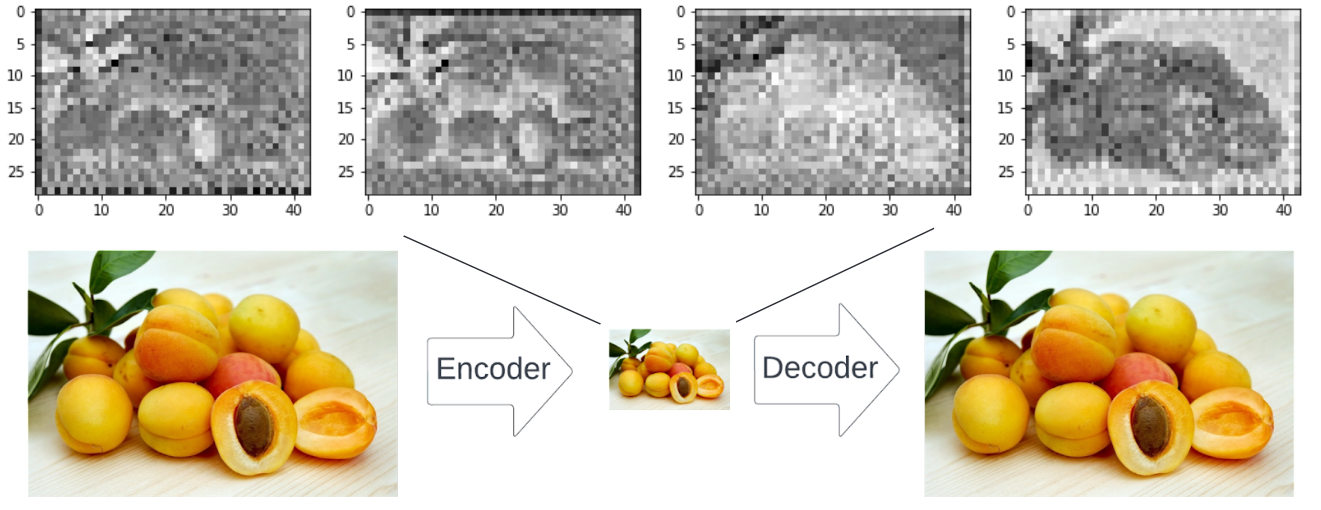
而这种用到的压缩/还原方式,也是一种模型,叫做 VAE。在 Stable Diffusion 中也经常用到,有一些 checkpoint 需要搭配特定的 VAE 使用,这种 VAE 提取了特定的图片特征,生成到”潜在空间“,方便对应的 checkpoint 模型进行更好的训练。所以在没有使用对应 VAE 的 checkpoint 的模型文件中,生成出来的图片总是会有一些颜色不对,此时 SD 检测到模型没有 VAE 所以使用了默认的,而默认 VAE 压缩的图片特征又难以和模型的训练方式对应。

我还见到过一些据说是可以修复手或脸部问题的 VAE,我还没有使用过,不过应该也不难理解,这类 VAE 在压缩和还原图片特征时,可能对手或脸部做了特殊处理,让效果更好。
总结
总之,AI 生成图片的过程可以参考下面这张图:
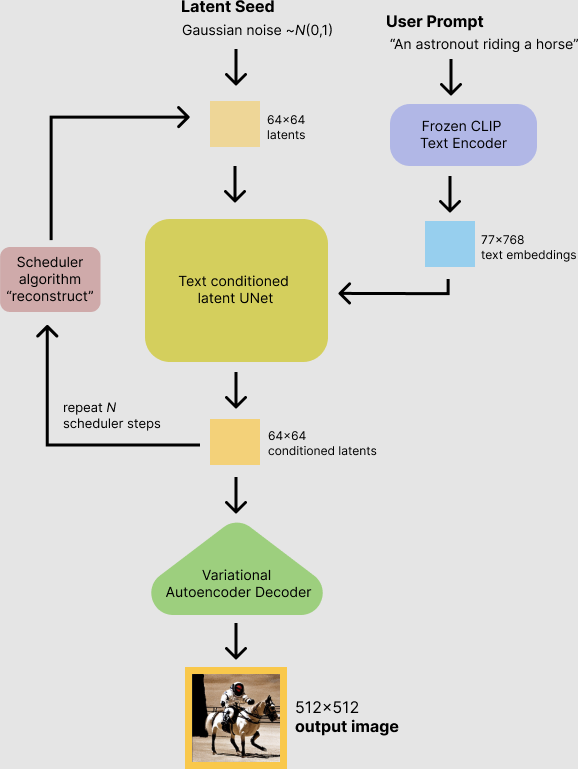
首先是在”潜在空间“生产噪声图,然后用 UNet 逐渐降噪,这里是一个循环,不断地迭代直到达到一个好的效果。当在”潜在空间“迭代到指定步数(Steps)之后,通过 VAE 将图像还原到正常人类可以理解的程度。
而模型的训练过程其实和生成图片的过程差不多,不过目前有好几种主流的训练方式,分别在不同的地方做了轻微调整。这些内容会单独拎出来做一节课,这里就不多做展开。
目前 Stable Diffusion 可以说是 LDM 模型最大的受益者,甚至从某种角度来说 LDM 等同于 Stable Diffusion 也不为过。正是 LDM 带来的低算力需求,让更多的三方开发者、模型训练师参与进来,进一步丰富了 Stable Diffusion 的生态。
参考资料
Learning Transferable Visual Models From Natural Language Supervision
OpenAI CLIP模型袖珍版,24MB实现文本图像匹配,iPhone上可运行
從頭開始學習Stable Diffusion:一個初學者指南
CLASSIFIER-FREE DIFFUSION GUIDANCE
在StableDiffusion中说起VAE时,我们在谈论什么?
Stable Diffusion VAE Guide and Comparison
Everything you need to know about stable diffusion
Stable Diffusion with 🧨 Diffusers
炜哥的AI学习笔记——SD基础原理