炜哥的AI学习笔记——Lora训练集准备
自从 5 月份从小鹏离职之后,就和几个朋友一起打算进行 AIGC 方面的创业,因此开始学习 Stable Diffusion 方面的知识。
但是目前互联网上对于 AI 绘图还没有系统的教程,尤其是模型训练方面的,所以我一遍学习一遍会记录笔记,并写成文章进行分享。
因为内容还比较多,所以暂时以文章的方式进行分享,如果学完之后发现有简化的可能,就考虑做成视频,重启之前做的《写给设计师的开发知识》系列,这个系列自从去年跳槽到小鹏之后就一直没时间更新。
训练模型使用工具:Kohya_ss GUI 版本
这个工具虽然相较于国内的一键炼丹工具复杂很多,但是却能够将训练过程中完整的参数设置和过程展示出来。更重要的是,国外的教程大部分也都是基于 Kohya 进行模型训练,能获取到的资料会丰富上一个量级,只是大部分的教程需要科学上网。
训练配置:GTX 3060 12G + i5 13400F
3060 相对来说是性价比很高的显卡了,同时加上 i5 处理器也可以保证在做一些其他任务(例如 Photoshop 处理)时能有较高的流畅度。SD 出图,512分辨率图片目前在 10s/张 左右。
训练集文件夹命名规则
训练集本质上是存储了一系列图片和图片标签的文件夹,当然,文件夹也需要按照一定的规则进行命名。
首先,需要决定你所训练内容的标识符(identifier)。例如,如果想要训练一种特别风格的狗,你可以为这个风格进行取名,例如 xxs,然后加上目标类别“dog”,然后训练假定为 50 次,那么训练集文件夹就是“50_xxs dog”。
命名规则直接来说就是:<repeat count>_<identifier> <class>
不过在 Lora 训练中,因为不怎么用到分类训练\正则化图像训练的方式,所以一般不怎么使用<class>

训练集素材命名建议
规范化命名。使用全英文+序号命名,全英文是为了训练软件能准确识别到,序号命名是为了后面整理起来方便。
统一尺寸。所有图片尺寸统一成一样的宽高,宽高最好保持在 512*512 上下。这里没有找到准确的理由,猜测是统一的尺寸可以减少计算机二次处理图片带来的压力,以及在二次处理图片时可能带来的一些特征损失。
尽量使用 PNG 图片。JPG 图片压缩过多,质量往往不是很高。不过也不需要可以将 JPG 转成 PNG,这样反而造成了又一层的损失。
训练集的标签
标签的作用
打标的本质是告诉 AI 画面中有什么内容。就好像一个画家要学习一个新画风,比如说水彩风,那我们教他的方式是拿一些常见的物品,比如小男孩、小女孩、花,告诉他这些常见的物品在水彩画风下是什么样子的,这样 AI 就可以理解并进行学习。
标签的格式
目前主流的打标还是使用机器自动生成+人工调整的方式。
而对于标签的格式,目前是有两种,自然语言描述和标签集描述。如果是使用 Stable Diffusion Webui 进行机器自动生成打标的话,对应的就是这下图两种选项。
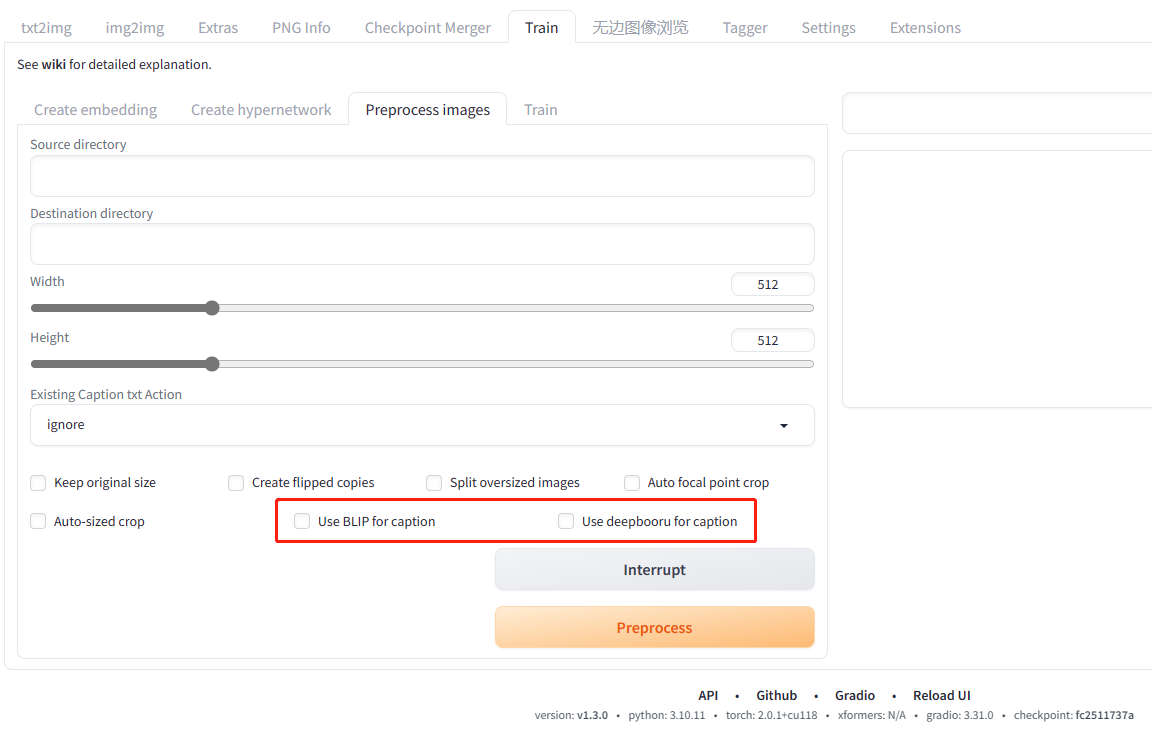
其中 BLIP 会生成自然语言描述,deepbooru 则是标签集描述。这两者并不是对立的,甚至可以全部勾选混在一起使用,不过大概率会出现描述重复。
两种方式各有利弊,就如何和人类沟通一样。如果使用带有主谓宾的完整语句和别人介绍事物,可以更好的介绍画面主体的一些行为,但是一些细微的特征则是会容易被忽略;而使用一系列的词语描述画面,可以较为全面的描述画面的内容,但是对于复杂的行为则很难用词语组说清楚。但这并不是绝对的,这就很考验语文功底。
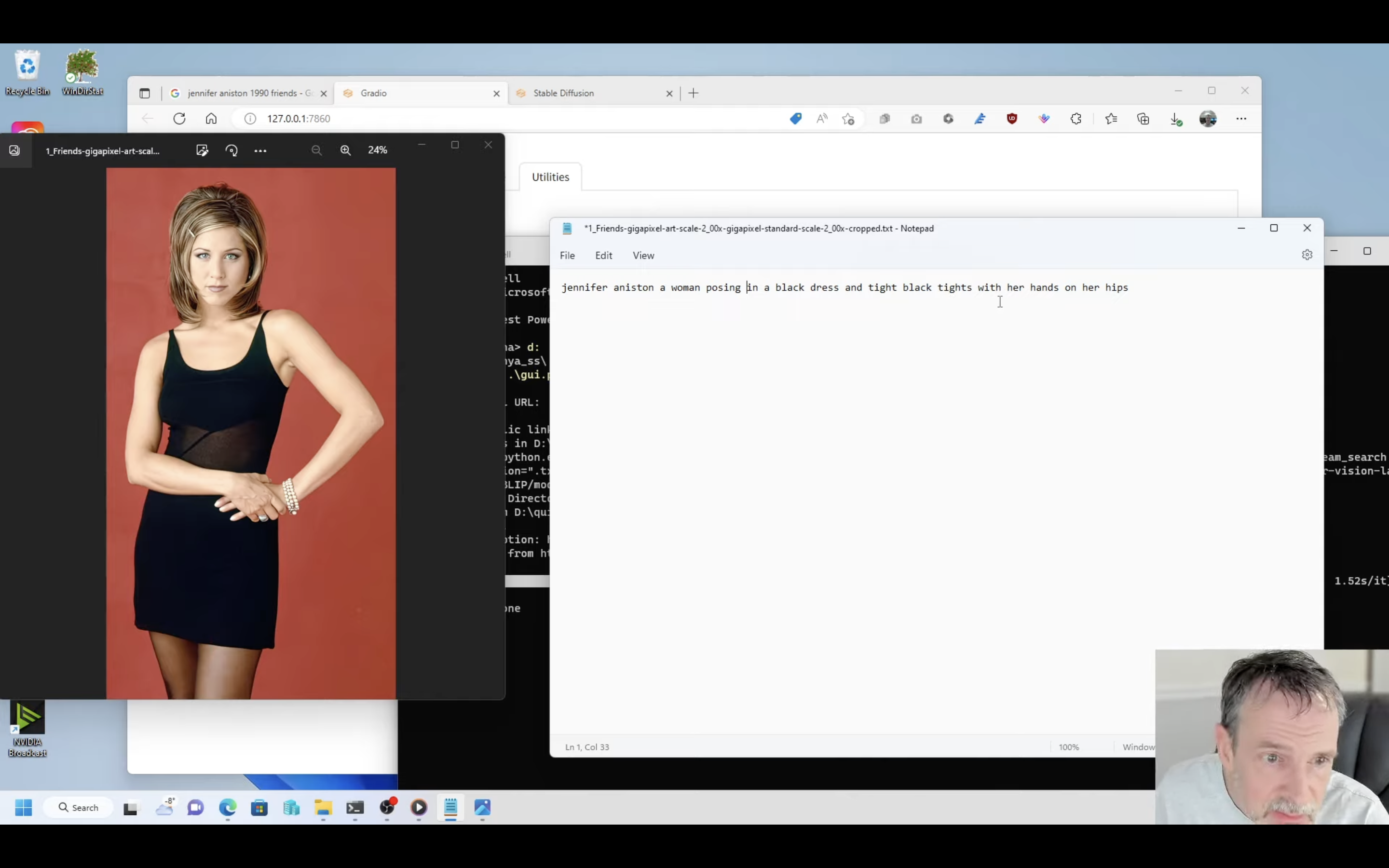
网上看到一种说法,说如果是训练人像的 Lora ,使用自然语言描述,比如 Kohya_ss 官方就使用了 Jennifer Aniston 的诸多照片进行训练(当然这并不建议,因为 Jennifer Aniston 作为一个知名人士,她的一些特征应该早已被底模收录,视频作者在后半段也有提及),其中使用的打标方法就是自然语言处理,使用自然语言可以对人物的姿态有一个较好的描述。
而国内的教程中,使用标签集打标的方式则是主流。
究其原因我想应该有两个,其一是国内目前的教程以二次元人物为主,这类人物往往会夸大一部分的特征,尤其是日系的人物,所以需要丰富的标签集来描述画面内容;其二是国内的语言问题,毕竟流畅的写出英语语句还是有一些门槛,而使用三方翻译软件翻译长句又可能出现一些细节上的错误,不如单词翻译精准。

当然,在我实际的训练过程中,一般不会使用默认的打标工具,而是使用三方插件(Tagger)进行更有效率的打标,不过这里不过多展开了。
然后说一下人工处理的部分。
首先就我个人的理解而言,标签并没有固定的格式,就像是你描述一个物体的特征,用整句整句的句子和散碎的词组都能向别人传达你的意思。
因此对于打标方式,我则是倾向于将两者结合,使用整句描述画面主体的内容,然后再辅以各种各样的标签描述画面的其他内容。这样既避免了长句难写、描述可能不全面的问题,也可以对画面主题的姿态有较好的描述。
举例:
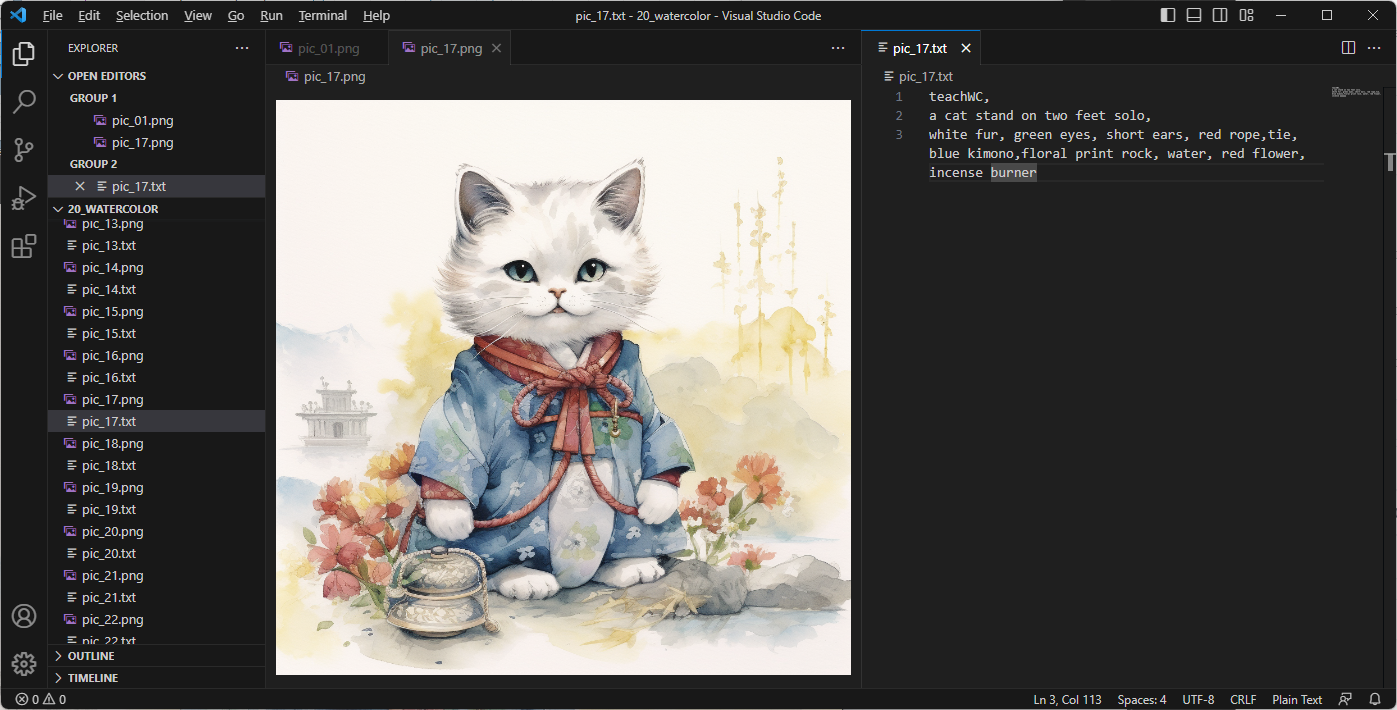
在对于这张图片进行描述的过程中,我将内容分为了三部分:
- 唤醒词。这里使用 teachWC 。至于唤醒词是什么,稍后进行介绍,这里不展开。
- 短句描述画面主体行为。图中的猫咪是双脚直立站着的,姿态稍微有些复杂,我使用短句描述这只猫的行为姿态。
- 词语组描述画面其他内容。接下来就是描述画面中的其他内容,我个人的习惯是从主体的外貌特征出发,然后到主体的衣着、周围的事物、背景内容、画面构图等,按照和主体的关联度依次描述。
标签正确性验证
如果有闲置且比较强大的算力,可以将找一个风格类似的大模型,将写完或写到一半的 tag (需要去除唤醒词)丢到 Stable Diffusion 中查看效果。这个效果和训练图放一起看,不求形似只求神似,只需要保证填写的 tag 所对应的内容都能够被 AI 所理解并在画面中出现。
还是上面的例子,我随便找了一个模型先看下效果。
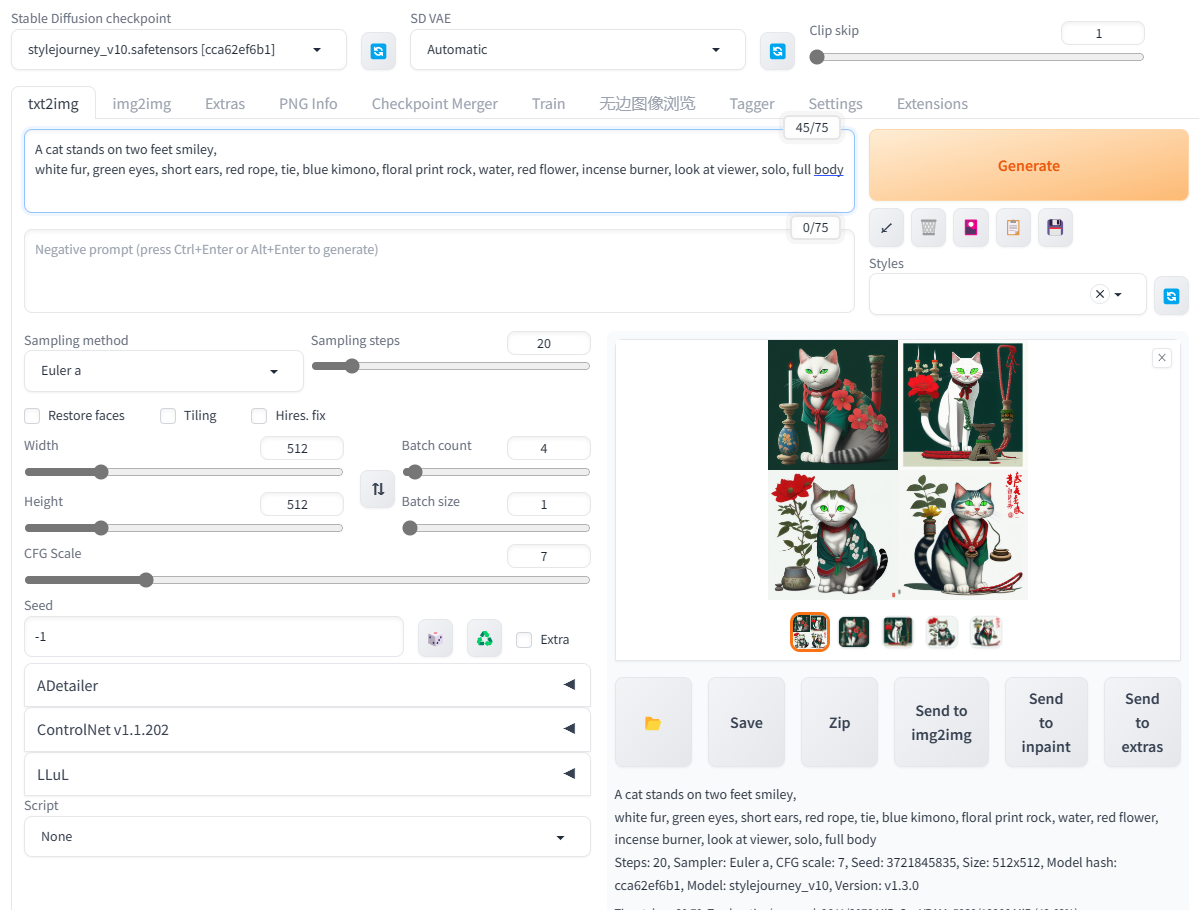
画面中的元素应该是都具备了,和训练的图片能对应上,除了双脚站立这一点。不过双脚站立的猫本身就不是常态,这个可以忽略(找了个二次元模型倒是能对应上,不过太色了不好放出来)。
唤醒词的使用
在标签的作用中提到,标签就是教给 AI “这张图里有什么”,换句话说,就是让 AI 将画面与标签关联上。唤醒词在这里的作用至关重要,我们训练集里的所有图片,不管是训练画风还是训练人物也好,都是围绕着一个“概念”来训练的(虽然也有训练多个概念的情况,但这里先简化不展开讲述),那么,我们需要在每个训练图片的标签中都打上一个词,让 AI 意识到“这个词语就代表着这个概念”。
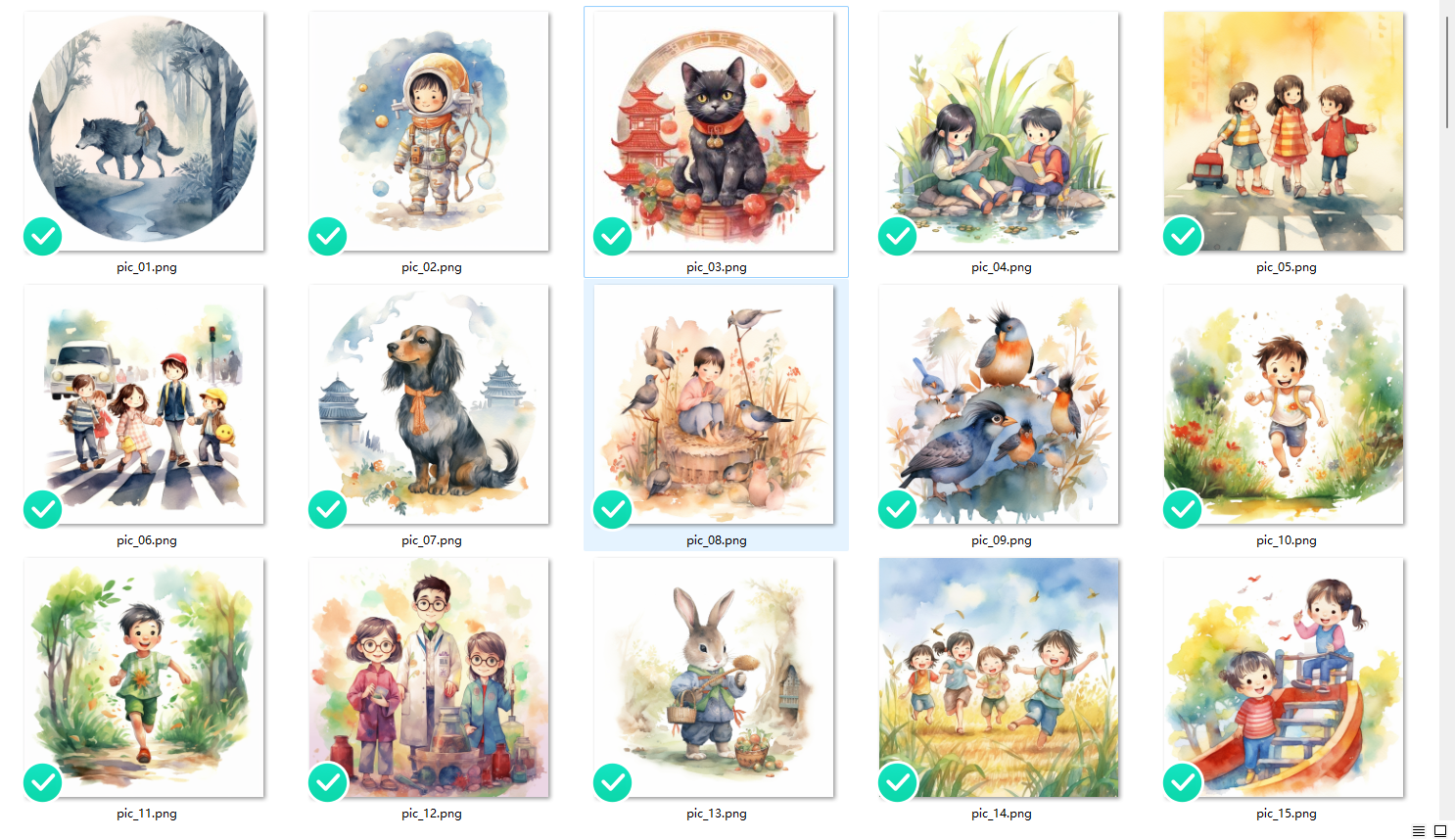
对于我这个例子来说,我希望 AI 学习到的概念是,“适用于教材的水彩风格的卡通插画”,所以我使用自己造的一个词语“teachWC”,来指代这个概念,并在每一张图的标签的最开始都加上了这个词语。
似乎越靠前的词语优先级越高,但是没有找到合理的说法来证实这一点。
将画面主体的标签放在第二个、剩余元素用关联度进行排序也是这个原因。
唤醒词可以自定义,但是需要注意词语的“偏僻性”,即不能使用常见的词语或词语组合作为唤醒词。我在之前使用过”teach watercolor”作为唤醒词,但是最终却出现了意想不到的效果——AI 对这个概念的学习不够深入。究其原因是 AI 在无法认知”teach watercolor”这个词语时,使用了近似的”watercolor“这个词的经验来学习,所以更加侧重学习到了水彩风格,而一定程度上忽视了其他我们想让它学习的概念。
可以设置多个唤醒词,在”多概念训练“中尤其有用,同样的这里也不展开讲了。
唤醒词设置后,在训练时需要将 “Keep n tokens”设置为唤醒词的个数,例如在这里我设置为 1。

在 Kohya_ss 中,这个选项具体的位置在:Training parameters - Advanced Configuration - Keep n tokens。
同样的,这个选项也没有找到合适的解释。不过将其从 0 设置为 1 之后,训练效果的确有所改进。
注意事项
在打标签的过程中,也发现了一些需要注意的地方。
- 把想要让 AI 学习的概念都包在唤醒词里即可。不需要对概念使用额外的唤醒词说明。
还是以“适用于教材的水彩风格的卡通插画”这个概念距离,正确的做法是讲这个概念直接包含在”teachWC“这个概念中。而如果在训练集中额外增加和这个概念相关的词语,例如加上 “watercolor,cute,illustration”,这样概念就被分割了,后续在模型实际应用时,除非看到完整的”teachWC,watercolor,cute,illustration”,AI 才会认为你希望它还原之前那个概念。
同时,因为“watercolor,cute,illustration”这些概念在底模中一定是有的,所以 AI 在学习的过程中难免会收到底模的影响,造成概念的“污染”。
- 人类都认不出来的事物就不用打标了。
还是以这张图片为例,我在这张图片中没有对背景的元素进行描述,因为我的确不知道背景在描写什么,这种情况下可以选择不写这一部分的标签,写了反而会对 AI 造成误导。比如对黄色的植物写一个“bamboo”,AI 会以为在这种风格下竹子就应该是黄色而且抽象的,若后续有生成竹子的需求那反而会造成反效果。
参考资料
炜哥的AI学习笔记——Lora训练集准备